编译原理概述
1. 什么是编译器
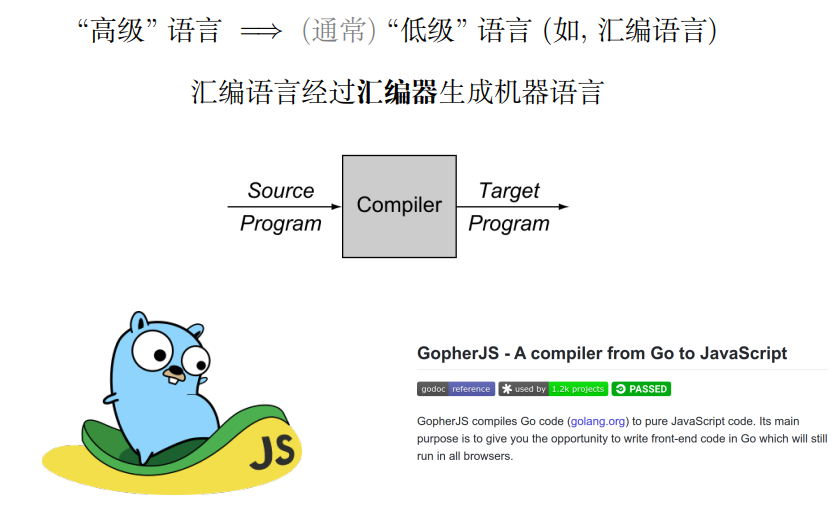
- 通常情况下是由高级语言编译到低级语言,但并不绝对,例如GopherJS
2. 机器语言是如何跑起来的
P1-P8:https://www.bilibili.com/video/BV1EW411u7th
3. 语言类应用程序
- 配置文件解析 (.properties)
- CSV 文件 (Comma-Separated Values)
- JSON 文件 (JavaScript Object Notation)
- SQL 引擎 (Structured Query Language)
- TLA+/TLAPS (TPaxos.tla)
- (Java) 字节码解释器
- C/C++ 语言编译器
- 排版工具 (LATEX)
- 绘图工具 (TikZ, Dot/Graphviz)
- L-System (Cantor Set)
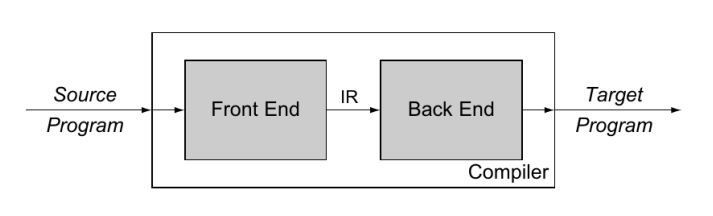
4. IR: Intermediate Representation (中间表示)
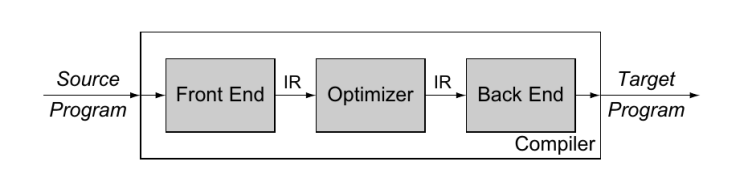
机器无关的中间表示优化
前端(分析阶段):分析源语言程序, 收集所有必要的信息
后端(综合阶段):利用收集到的信息, 生成目标语言程序
在设计实际生产环境中的编译器时, 优化通常占用了大多数时间
5. 词法、语法、语义和物理定律
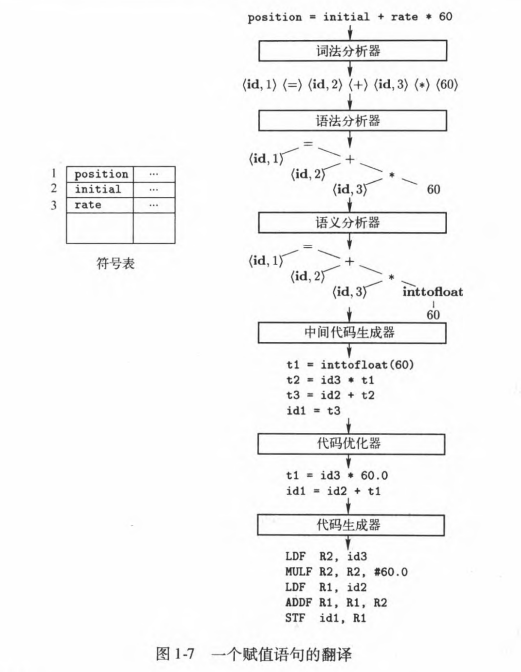
作为一名程序员,你看到了什么?
position = initial + rate ∗ 60
- 词法: 标识符、数字、运算符
- 语法: 包含算术运算的赋值语句
- 语义: position, initial, rate 是数值类型
- 物理定律: 当前位置 = 初始位置 + 速度 × 时间
我们希望编译器可以懂词法、语法、语义,但是作为编译器, 它仅仅看到了一个字符串
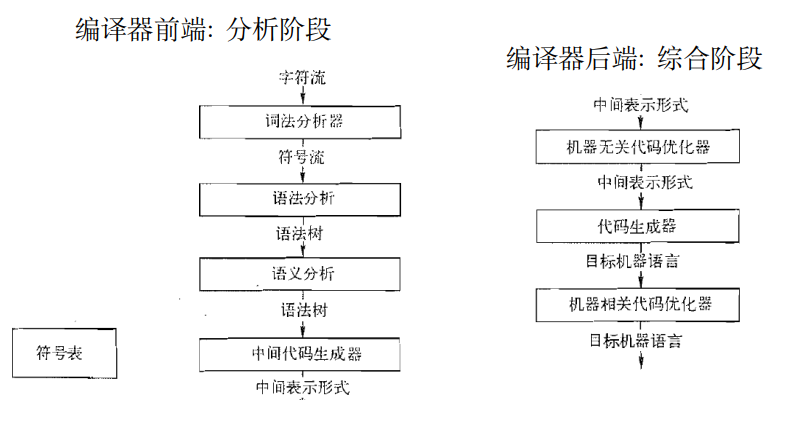
5.1 词法分析器
词法分析器 (Lexer/Scanner): 将字符流转化为词法单元(token)流。
<id,1>
- id:表示标识符(identifier)的抽象符号
- 1:指向符号表中position对应的条目。

5.2 语法分析器
语法分析器 (Parser): 构建词法单元之间的语法结构, 生成语法树
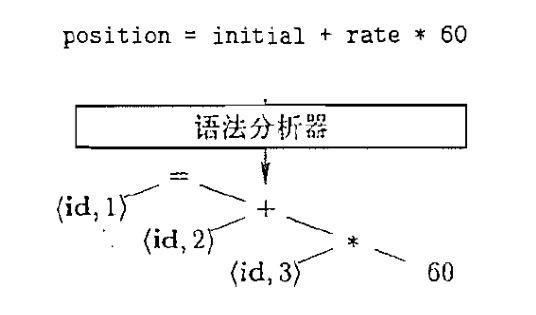
5.3 语义分析器
语义分析器: 语义检查, 如类型检查、”先声明后使用”约束检查
程序设计语言可能允许某些类型转换,这被称为自动类型转换(coercion)
假设position、initial和rate已被声明为浮点数类型,而词素60本身形成一个整数。
语义分析器的类型检查程序发现运算符 * 被用于一个浮点数 rate 和一个整数 60。在这种情况下,这个整数可以被转换成为一个浮点数。
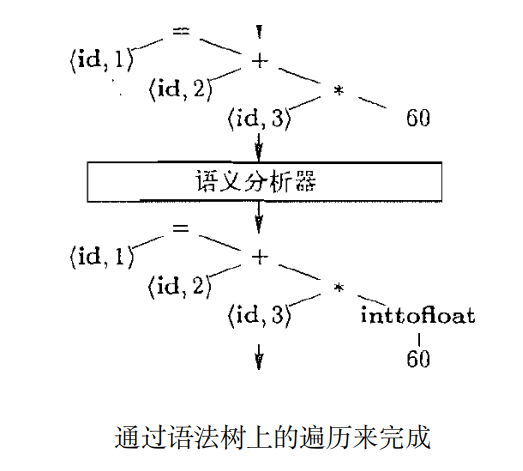
5.4 中间代码生成器
中间代码生成器: 生成中间代码, 如 “三地址代码”
“三地址代码”,这种中间表示由一组类似于汇编语言的指令组成,每个指令具有三个运算分量。每个运算分量都像一个寄存器。
关于三地址指令,有几点是值得专门指出的。
首先,每个三地址赋值指令的右部最多只有一个运算符。因此这些指令确定了运算完成的顺序。在源程序中,乘法应该在加法之前完成。
第二,编译器应该生成一个临时名字以存放一个三地址指令计算得到的值。
第三,有些三地址指令的运算分量的少于三个(比如下面的序列中的第一个和最后一个指令)。
中间代码类似目标代码, 但不含有机器相关信息 (如寄存器、指令格式)
中间表示应该具有两个重要的性质:
- 易于生成
- 能够被轻松地翻译为目标机器上的语言。
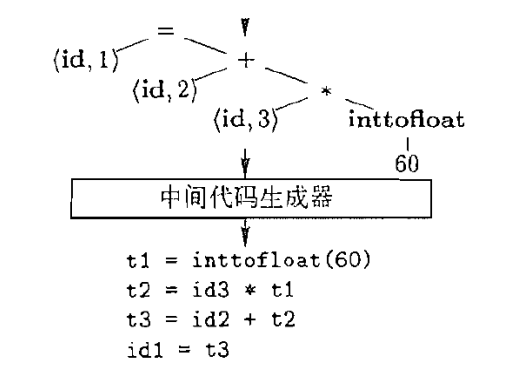
5.5 中间代码优化器
编译时计算、消除冗余临时变量
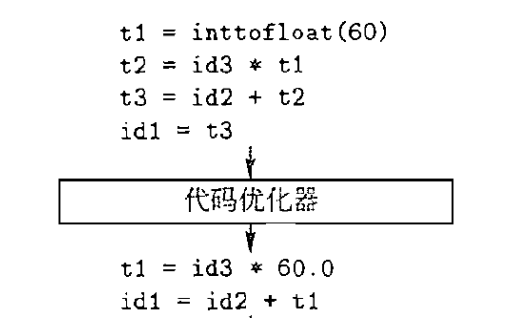
5.6 代码生成器
代码生成器: 生成目标代码, 主要任务包括指令选择、寄存器分配

5.7 符号表
符号表: 收集并管理变量名/函数名相关的信息
变量名: 类型、寄存器、内存地址、行号
函数名: 参数个数、参数类型、返回值类型
符号表:红黑树(RB-Tree)、哈希表(Hashtable)

为了方便表达嵌套结构与作用域, 可能需要维护多个符号表

补充内容
龙书:
1.1 语言处理器
- 解释器(interpreter)是另一种常见的语言处理器。它并不通过翻译的方式生成目标程序。
- 从用户的角度看,解释器直接利用用户提供的输入执行源程序中指定的操作。
- 在把用户输入映射成为输出的过程中,由一个编译器产生的机器语言目标程序通常比一个解释器快很多。然而,解释器的错误诊断效果通常比编译器更好,因为它逐个语句地执行源程序。
Java语言处理器结合了编译和解释过程,一个Java源程序首先被编译成一个称为字节码(bytecode)的中间表示形式。然后由一个虚拟机对字节码加以解释执行。
为了更快地完成输入到输出的处理,有些被称为即时(just in time)编译器的Java编译器在运行中间程序处理输入的前一刻首先把字节码翻译成为机器语言,然后再执行程序
一个源程序可能被分割成为多个模块,并存放于独立的文件中。把源程序聚合在一起的任务有时会由一个被称为预处理器(preprocessor)的程序独立完成。预处理器还负责把那些称为宏的缩写形式转换为源语言的语句。
一个文件中的代码可能指向另一个文件中的位置,而链接器(linker)能够解决外部内存地址的问题。最后,加载器(loader)把所有的可执行目标文件放到内存中执行。
1.2 一个编译器的结构
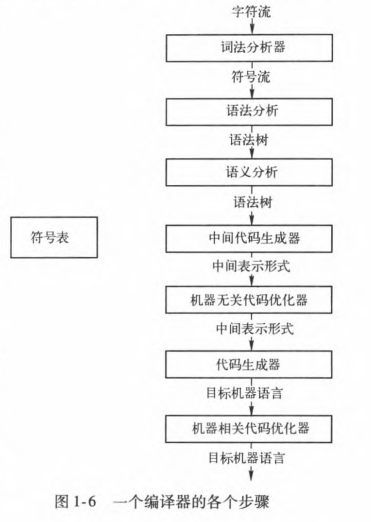
自制编译器:
1. 可执行文件
现代的 Linux 上的可执行文件,通常是指符合 ELF(Executable and Linking Format)这种特定形式的文件。
- ls、cp 这些命令(command)对应的实体文件都是可执行文件,例如 /bin/ls 和 /bin/cp 等。
- 使用 file 命令能够查看文件是否符合 ELF 的形式。会显示 ELF……executable
ELF 文件中包含了程序(代码)以及如何运行该程序的相关信息(元数据)。程序(代码)就是机器语言(machine language)的列表。
- GCC 将 C 语言的程序转化为用机器语言(例如 486 的机器语言)描述的程序。将机器语言的程序按照 ELF 这种特定的文件格式注入文件,得到的就是可执行文件。
2. 编译
gcc 命令是如何将 hello.c 转换为可执行文件的呢?
C 语言的代码经过预处理、编译、汇编、链接这 4 个阶段的处理,最终生成可执行文件。
预处理
先由预处理器(preprocessor)对 #include 和 #define 进行处理。
- 具体来说,读入头文件,将所有的宏展开,这就是预处理(preprocess)
- 预处理的内容近似于 sed 命令和 awk 命令这样的纯文本操作,不考虑 C 语言语法的含义。
狭义的编译
编译器对预处理器的输出进行编译,生成汇编语言(assemble language)的代码。一般来说,汇编语言的代码的文件扩展名是“.s”。
汇编
汇编语言的代码由汇编器(assembler)转换为机器语言,这个处理过程称为汇编(assemble)。
汇编器的输出称为目标文件(object file)。一般来说,目标文件的扩展名是“.o”。
Linux 中,目标文件也是 ELF 文件。既然都是 ELF 文件,那么如何区分是目标文件还是可执行文件呢?
ELF 文件中有用于提示文件种类的标志。例如, 用 file 命令来查看目标文件,会显示 ELF…relocatable,据此就能够将其和可执行文件区分开。
链接
目标文件本身还不能直接使用,无论是直接运行还是作为程序库(library)文件调用都不可以。
将目标文件转换为最终可以使用的形式的处理称为链接(link)。使用程序库的情况下,会在这个阶段处理程序库的加载
3. 程序运行环境
链接的话题并非仅仅出现在 build 的过程中。如果使用了共享库,那么在开始运行程序时,链接才会发生。最近广泛使用的动态加载(dynamic load),就是一种将所有链接处理放到程序运行时进行的手法。
在 Sun 的 Java VM 等具有代表性的 Java 的运行环境中,为了提高运行速度,采用了 JIT 编译器(Just In Time compiler)。JIT 编译器是在程序运行时进行处理,将程序转换为机器语言的编译器。也就是说,Java 语言是在运行时进行编译的。