第三章 存储管理
3.1 存储管理基础
3.1.1 存储管理的主要模式
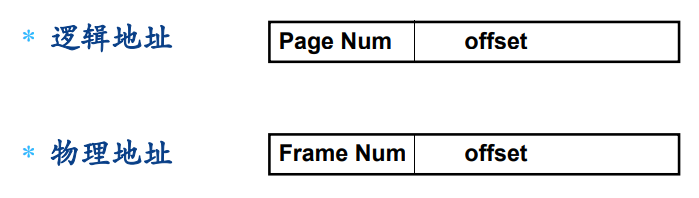
逻辑地址
- 逻辑地址:又称相对地址,即用户编程所使用的地址空间
- 逻辑地址从0开始编号,有两种形式
- 一维逻辑地址(地址)
- 二维逻辑地址(段号:段内地址)
段式程序设计
- 把一个程序设计成多个段
- 代码段、数据段、堆栈段、等等
- 用户可以自己应用段覆盖技术扩充内存空间使用量
- 段覆盖技术:用户在程序设计时包括主程序段、堆栈段、多个子程序段和数据段,而执行程序时只调入主程序段、堆栈段与需要的子程序段和数据段,并根据执行的需要,由程序设计者预先设计的代码动态决定哪些段调入内存
- 这一技术是程序设计技术,不是OS存储管理的功能
物理地址
- 物理地址:又称绝对地址,即程序执行所使用的地址空间
- 处理器执行指令时按照物理地址进行
主存储器的复用
- 多道程序设计需要复用主存
- 按照分区复用:
- 主存划分为多个固定/可变尺寸的分区
- 一个程序/程序段占用一个分区
- 按照页架(页框)复用:
- 主存划分成多个固定大小的页架
- 一个程序/程序段占用多个页架
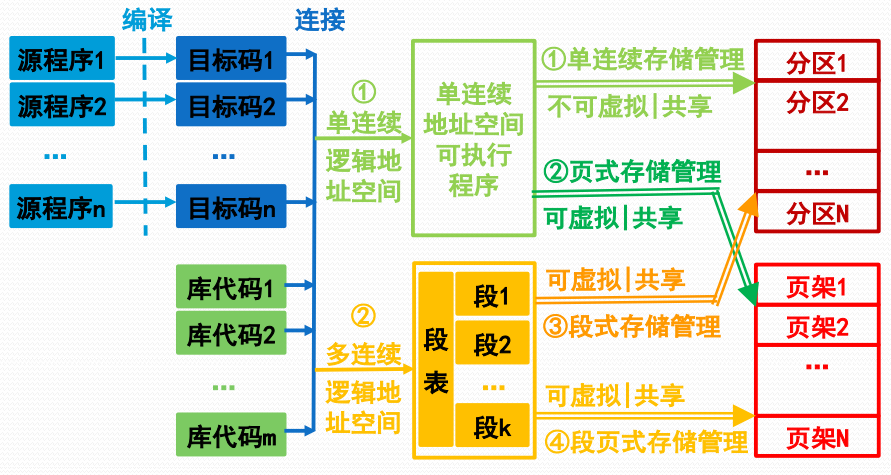
存储管理的基本模式
- 单连续存储管理:一维逻辑地址空间的程序占用一个主存固定分区或可变分区
- 段式存储管理:段式二维逻辑地址空间的程序占用多个主存可变分区
- 页式存储管理:一维逻辑地址空间的程序占用多个主存页架区
- 段页式存储管理:段式二维逻辑地址空间的程序占用多个主存页架区
存储管理模式示意图
3.1.2 存储管理的功能
地址转换
- 地址转换:又称重定位,即把逻辑地址转换成绝对地址
静态重定位:在程序装入内存时进行地址转换
- 由装入程序执行,早期小型OS使用
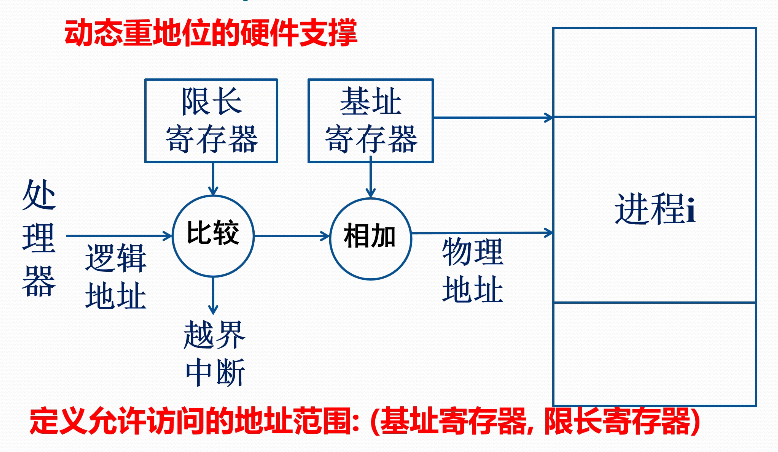
动态重定位:在CPU执行程序时进行地址转换
- 从效率出发,依赖硬件地址转换机构
主存储器空间的分配与去配
- 分配:进程装入主存时,存储管理软件进行具体的主存分配操作,并设置一个表格记录主存空间的分配情况
- 去配:当某个进程撤离或主动归还主存资源时,存储管理软件要收回它所占用的全部或者部分存储空间,调整主存分配表信息
主存储器空间的共享
- 多个进程共享主存储器资源:多道程序设计技术使若干个程序同时进入主存储器,各自占用一定数量的存储空间,共同使用一个主存储器
- 多个进程共享主存储器的某些区域:若干个协作进程有共同的主存程序块或者主存数据块
存储保护
- 为避免主存中的多个进程相互干扰,必须对主存中的程序和数据进行保护
- 私有主存区中的信息:可读可写
- 公共区中的共享信息:根据授权
- 非本进程信息:不可读写
- 这一功能需要软硬件协同完成
- CPU检查是否允许访问,不允许则产生地址保护异常,由OS进行相应处理
主存储器空间的扩充
- 主存扩充:把磁盘作为主存扩充,只把部分进程或进程的部分内容装入内存
- 对换技术:把部分不运行的进程调出
- 虚拟技术:只调入进程的部分内容
- 这一工作需要软硬件协作完成
- 对换进程决定对换,硬件机构调入
- CPU处理到不在主存的地址,发出虚拟地址异常,OS将其调入,重执指令
3.1.3 虚拟存储器的概念
虚拟存储器思想的提出
- 主存容量限制带来诸多不便
- 用户编写程序必须考虑主存容量限制
- 多道程序设计的道数受到限制
- 用户编程行为分析
- 全面考虑各种情况,执行时有互斥性
- 顺序性和循环性等空间局部性行为
- 某一阶段执行的时间局部性行为
- 因此可以考虑部分调入进程内容
虚拟存储器的基本思想
- 存储管理把进程全部信息放在辅存中,执行时先将其中一部分装入主存,以后根据执行行为随用随调入
- 如主存中没有足够的空闲空间,存储管理需要根据执行行为把主存中暂时不用的信息调出到辅存上去
虚拟存储器的实现思路
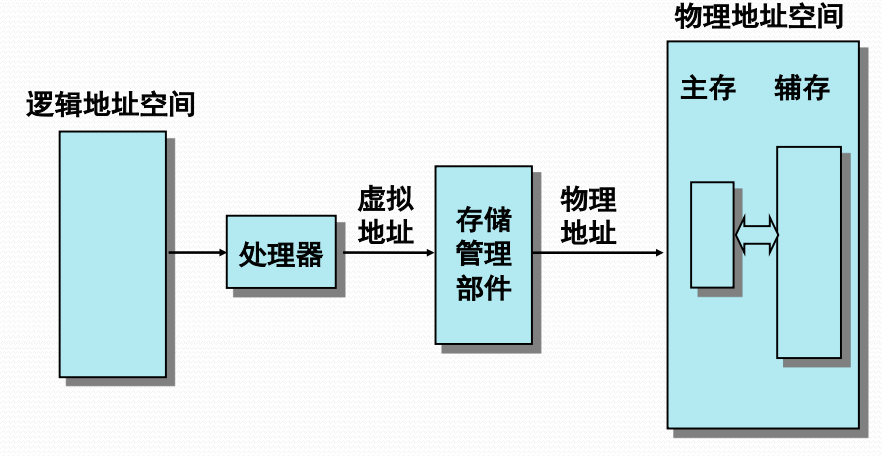
- 需要建立与自动管理两个地址空间
- (辅存)虚拟地址空间:容纳进程装入
- (主存)实际地址空间:承载进程执行
- 对于用户,计算机系统具有一个容量大得多的主存空间,即虚拟存储器
- 虚拟存储器是一种地址空间扩展技术,通常意义上对用户编程是透明的,除非用户需要进行高性能的程序设计
虚拟存储器示意
3.1.4 存储管理的硬件支撑
存储器的组织层次
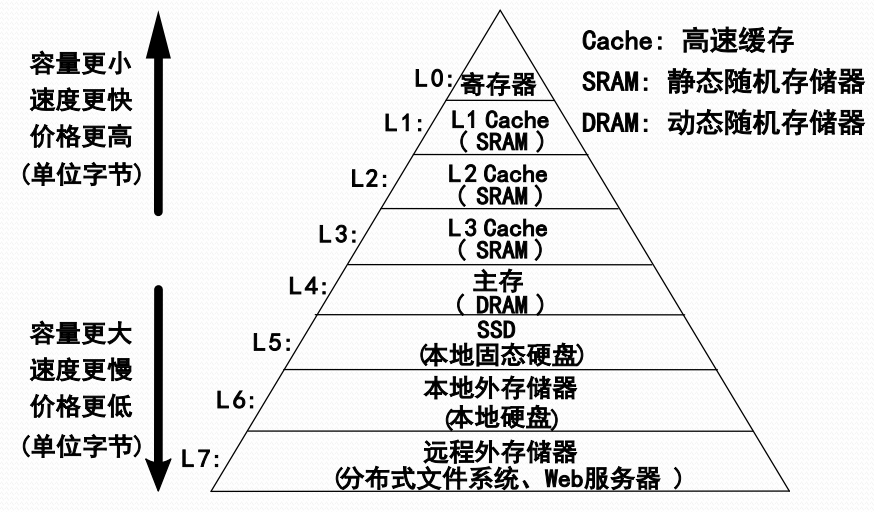
存储管理涉及的存储对象
- 存储管理是OS管理主存储器的软件部分
- 为获得更好的处理性能,部分主存程序与数据(特别是关键性能数据)被调入Cache,存储管理需要对其进行管理,甚至包括对联想存储器的管理
- 为获得更大的虚拟地址空间,存储管理需要对存放在硬盘、固态硬盘、甚至网络硬盘上的虚拟存储器文件进行管理
高速缓存存储器(Cache)
- Cache是介于CPU和主存储器间的高速小容量存储器,由静态存储芯片SRAM组成,容量较小但比主存DRAM技术更加昂贵而快速,接近于CPU的速度
- CPU往往需要重复读取同样的数据块,Cache的引入与缓存容量的增大,可以大幅提升CPU内部读取数据的命中率,从而提高系统性能
高速缓存存储器的构成
- 高速缓存存储器通常由高速存储器、联想存储器、地址转换部件、替换逻辑等组成
- 联想存储器:根据内容进行寻址的存储器
- 地址转换部件:通过联想存储器建立目录表以实现快速地址转换。命中时直接访问Cache;未命中时从内存中读取放入Cache
- 替换部件:在缓存已满时按一定策略进行数据块替换,并修改地址转换部件
高速缓存存储器的组织
- 由于CPU芯片面积和成本,Cache很小
- 根据成本控制,划分为L1、L2、L3三级
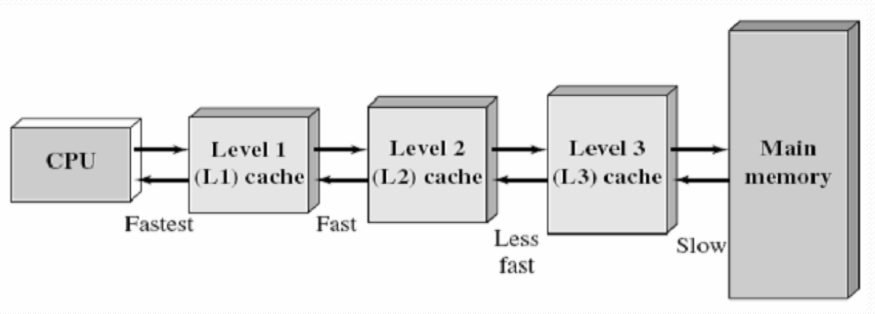
高速缓存存储器的分级
- L1 Cache:分为数据缓存和指令缓存;内置;其成本最高,对CPU的性能影响最大;通常在32KB-256KB之间
- L2 Cache:分内置和外置两种,后者性能低一些;通常在512KB-8MB之间
- L3 Cache:多为外置,在游戏和服务器领域有效;但对很多应用来说,总线改善比设置L3更加有利于提升系统性能
各类处理器架构
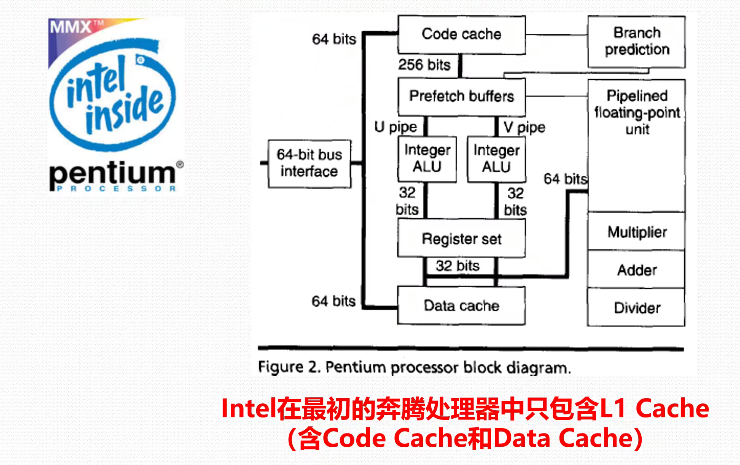
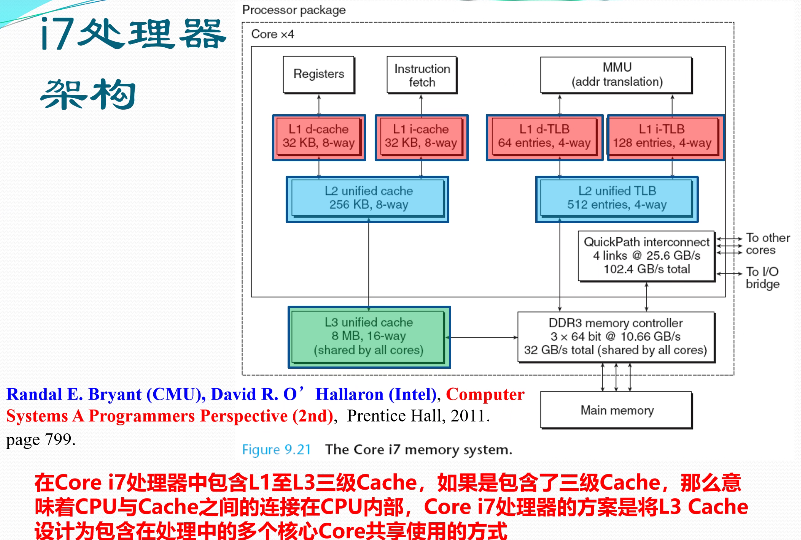
地址转换/存储保护的硬件支撑
存储管理与硬件支撑
- 鉴于程序执行与数据访问的局部性原理,存储管理软件使用Cache可以大幅度提升程序执行效率
动态重定位、存储保护等,若无硬件支撑在效率上是无意义的,即无实现价值
无虚拟地址中断,虚拟存储器无法实现
- 无页面替换等硬件支撑机制,虚拟存储器在效率上是无意义的
3.2 单连续分区存储管理
3.2.1 单连续分区存储管理
单连续分区存储管理
- 每个进程占用一个物理上完全连续的存储空间(区域)
- 单用户连续存储管理
- 固定分区存储管理
- 可变分区存储管理
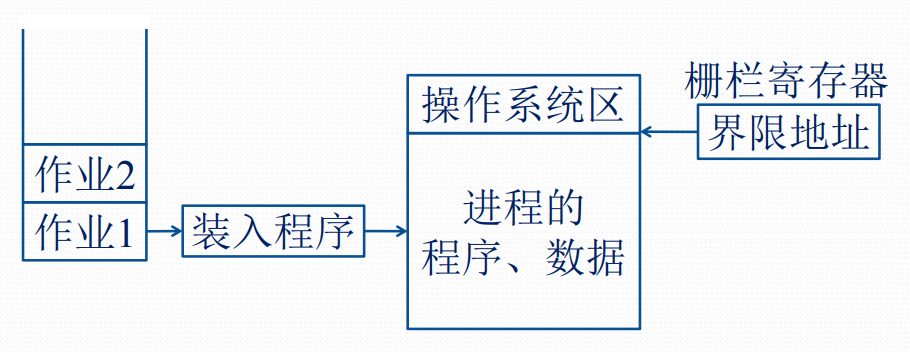
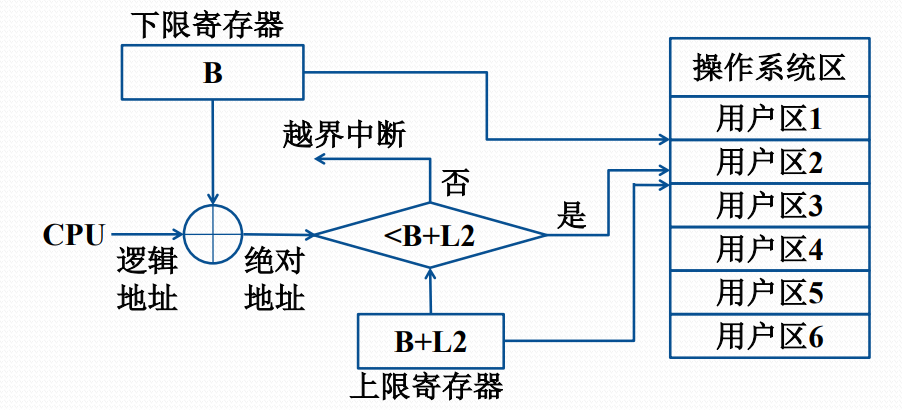
单用户连续分区存储管理
- 主存区域划分为系统区与用户区
- 设置一个栅栏寄存器界分两个区域,硬件用它在执行时进行存储保护
- 一般采用静态重定位进行地址转换
- 硬件实现代价低
- 适用于单用户单任务操作系统,如DOS
单用户连续分区存储管理示意
- 静态重定位:在装入一个作业时,把该作业中程序的指令地址和数据地址全部转换成绝对地址
固定分区存储管理的基本思想
- 支持多个分区
- 分区数量固定
- 分区大小固定
- 可用静态重定位
- 硬件实现代价低
- 早期OS采用
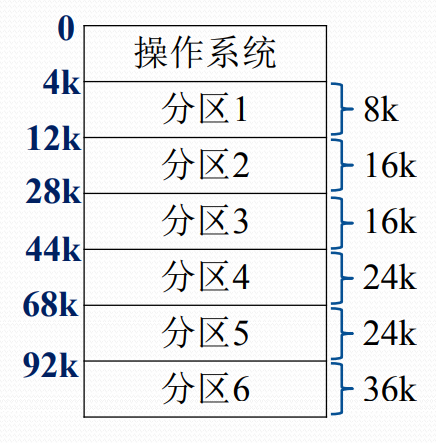
固定分区方式的主存分配
主存分配表
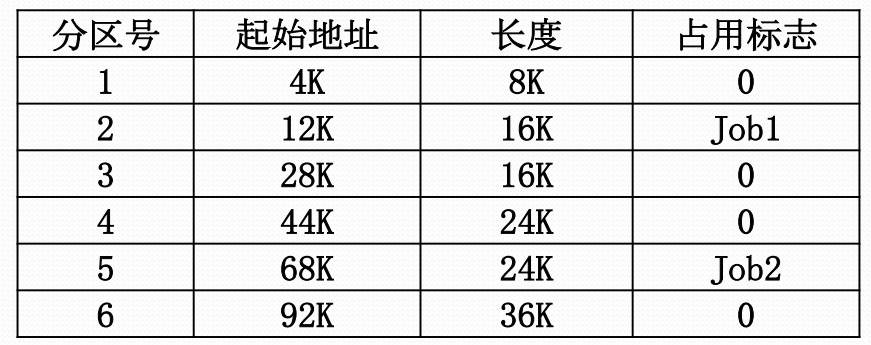
主存分配与去配
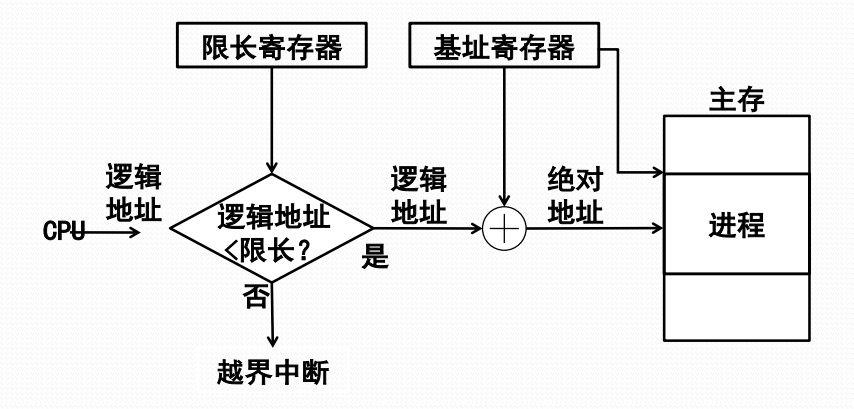
固定分区方式的地址转换
硬件实现机制与动态重定位
可变分区存储管理概述
固定分区存储管理不够灵活,既不适应大尺寸程序,又存在内存内零头,有浪费
能否按照进程实际内存需求动态划分分区,并允许分区个数可变
这就是可变分区存储管理
3.2.2 可变分区存储管理
可变分区存储管理
- 按进程的内存需求来动态划分分区
- 创建一个进程时,根据进程所需主存量查看主存中是否有足够的空闲空间
- 若有,则按需要量分割一个分区
- 若无,则令该进程等待主存资源
- 由于分区大小按照进程实际需要量来确定,因此分区个数是随机变化的
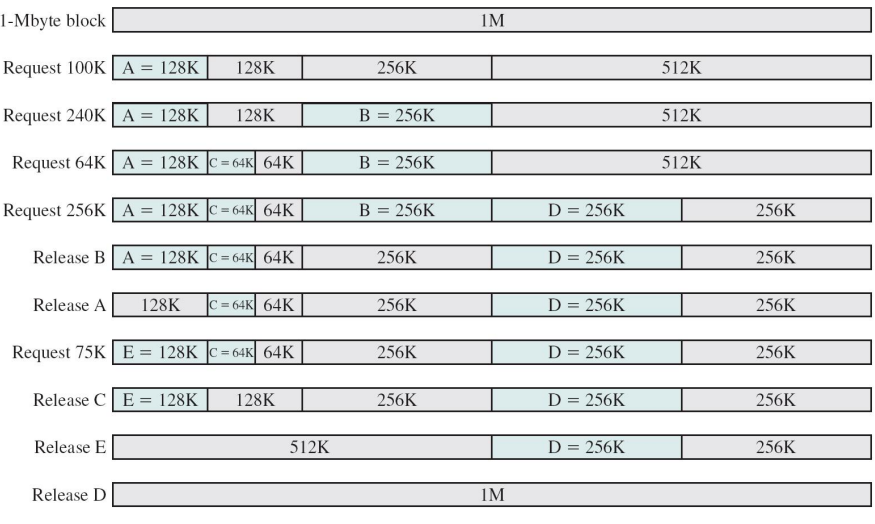
可变分区方式的内存分配示例
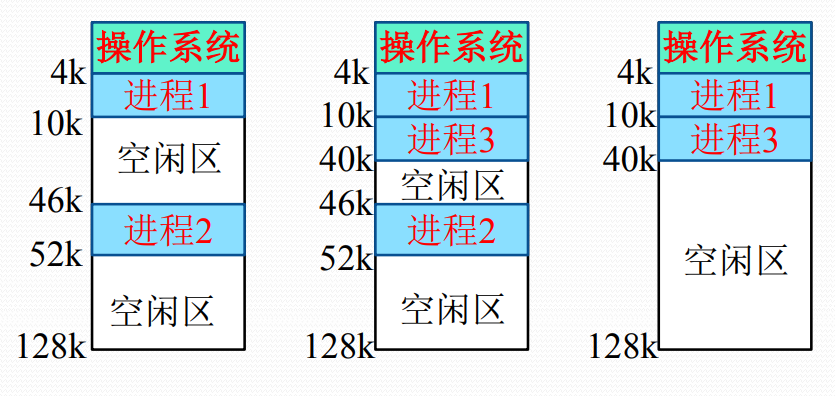
可变分区方式的主存分配表
- 已分配区表与未分配区表,采用链表
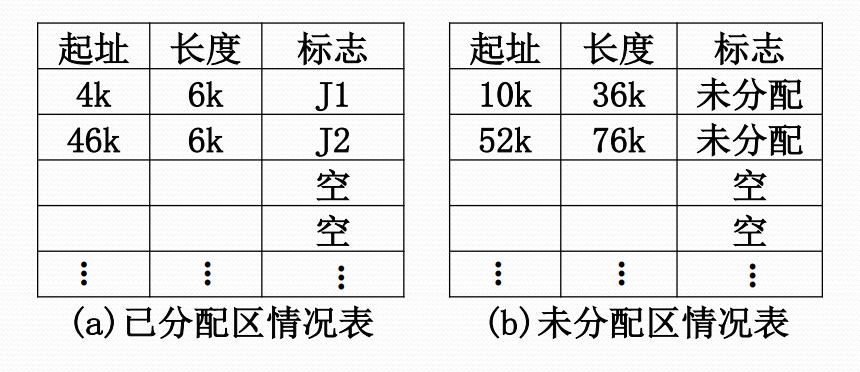
可变分区方式的内存分配
- 最先适应分配算法
- 从低地址向高地址扫描,所查找到的第一个可以容纳该进程的空闲区就分配给进程
- 邻近适应分配算法
- 从上一次分配的地址开始向高地址查找符合要求的空闲区,所查找到的第一个满足要求的空闲区就分配给进程。
- 最优适应分配算法
- 选择内存空闲区中最适合进程大小的分配。
- 最坏适应分配算法
- 挑选最大的空闲区
可变分区方式的内存回收
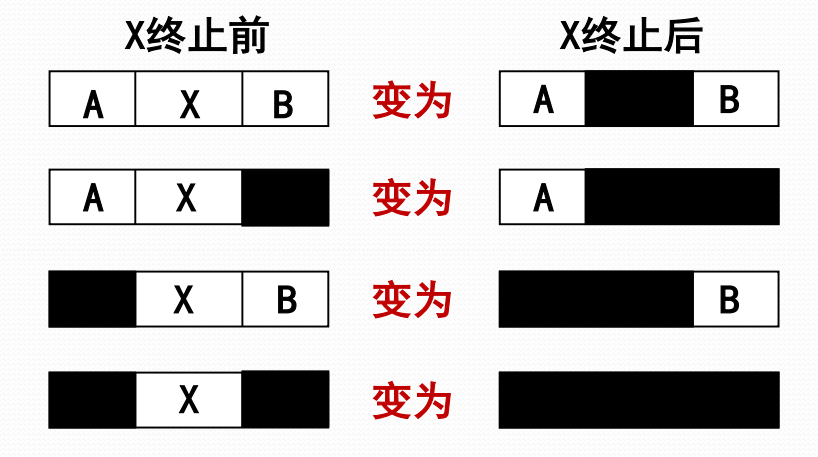
地址转换与存储保护
- 硬件实现机制与动态重定位
可变分区方式的内存零头
- 固定分区方式会产生内存内零头
- 可变分区方式也会随着进程的内存分配产生一些小的不可用的内存分区,称为内存外零头
- 最优适配算法最容易产生外零头
- 任何适配算法都不能避免产生外零头
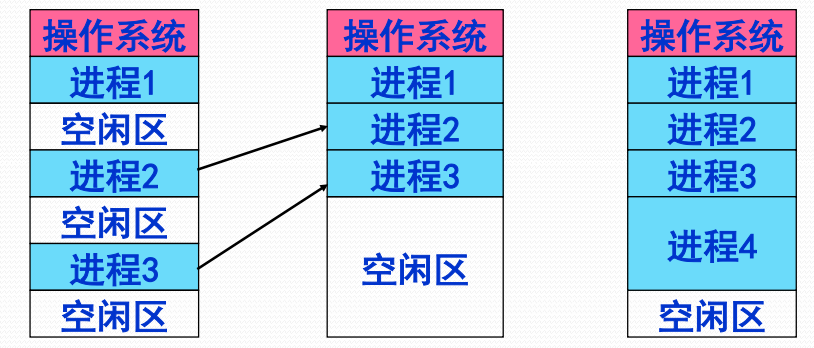
移动技术(程序浮动技术)
- 移动分区以解决内存外零头
- 需要动态重定位支撑
移动技术的工作流程

3.3 页式存储管理
3.3.1 页式存储管理的基本原理
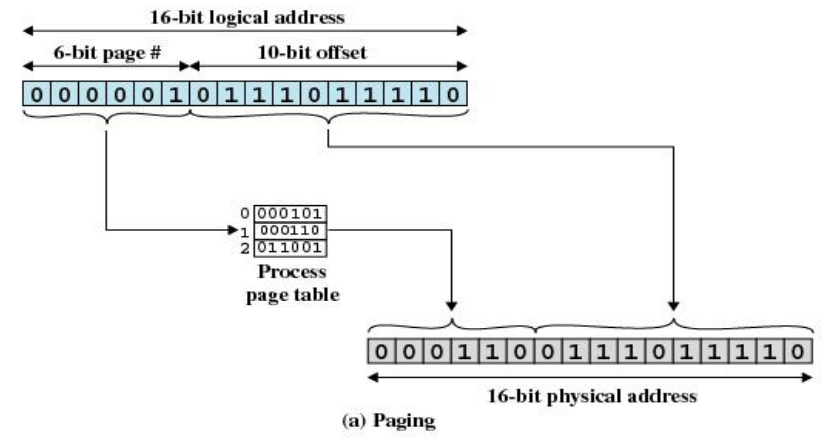
页式存储管理的基本原理
分页存储器将主存划分成多个大小相等的页架
受页架尺寸限制,程序的逻辑地址也自然分成页
不同的页可以放在不同页架中,不需要连续
页表用于维系进程的主存完整性

页式存储管理中的地址
页式存储管理的逻辑地址由两部分组成,页号和单元号(页内偏移量 offset),逻辑地址形式:

页式存储管理的物理地址也有两部分组成:页架号和单元号,物理地址形式:

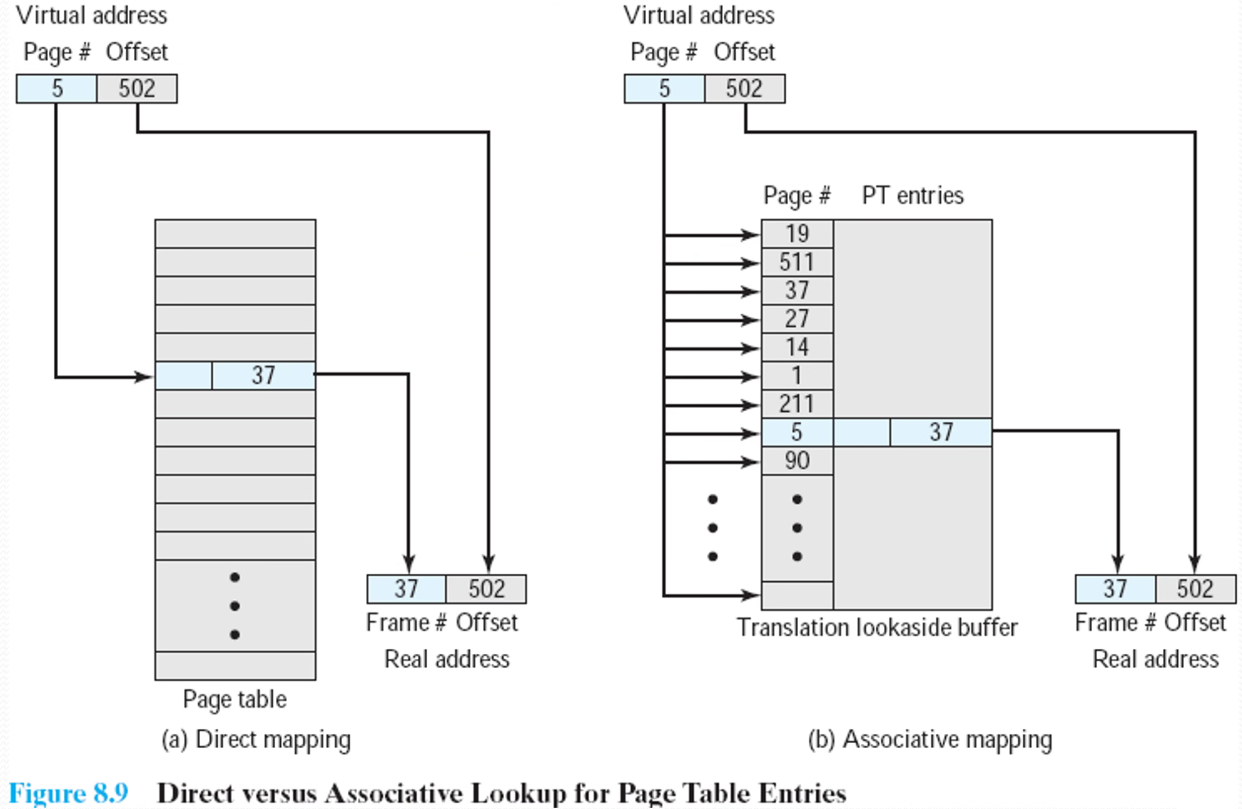
地址转换可以通过查页表完成
- 页内地址逐一连续对应
- 所以地址转换时只需要从页号映射到页框号
页式存储管理的地址转换思路
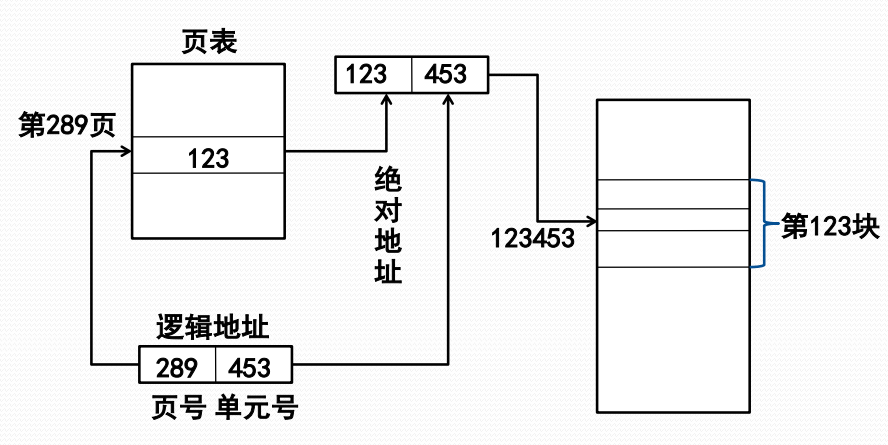
页式存储管理的内存分配/去配
- 可用一张位示图来记录主存分配情况
- 建立进程页表维护主存逻辑完整性
页的共享
页式存储管理能够实现多个进程共享程序和数据
数据共享:不同进程可以使用不同页号共享数据页
- 允许不同进程对共享的数据页用不同的页号,只要让各自页表中的有关表项指向共享的数据页框
程序共享:不同进程必须使用相同页号共享代码页
- 共享代码页中的(JMP <页内地址>)指令,使用不同页号是做不到
- 由于指令包含指向其他指令或数据的地址,进程依赖于这些地址才能执行,不同进程中正确执行共享代码页面,必须为它们在所有逻辑地址空间中指定同样页号
3.3.2 页式存储管理的地址转换
页式存储管理的地址转换代价
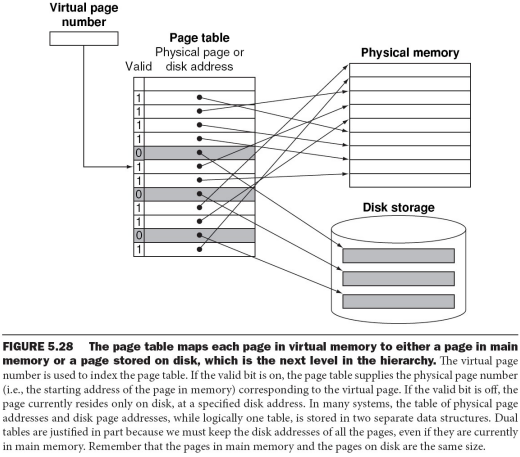
页表放在主存: 每次地址转换必须访问两次主存
按页号读出页表中的相应页架号
按计算出来的绝对地址进行读写
存在问题:降低了存取速度
解决办法:利用Cache存放部分页表
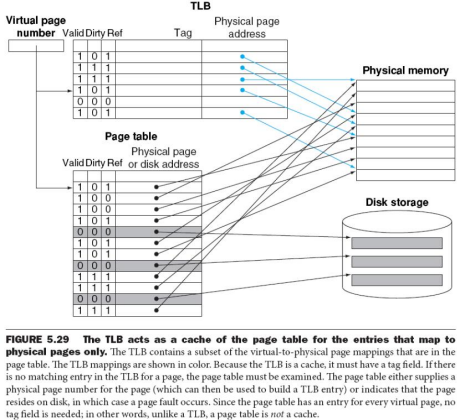
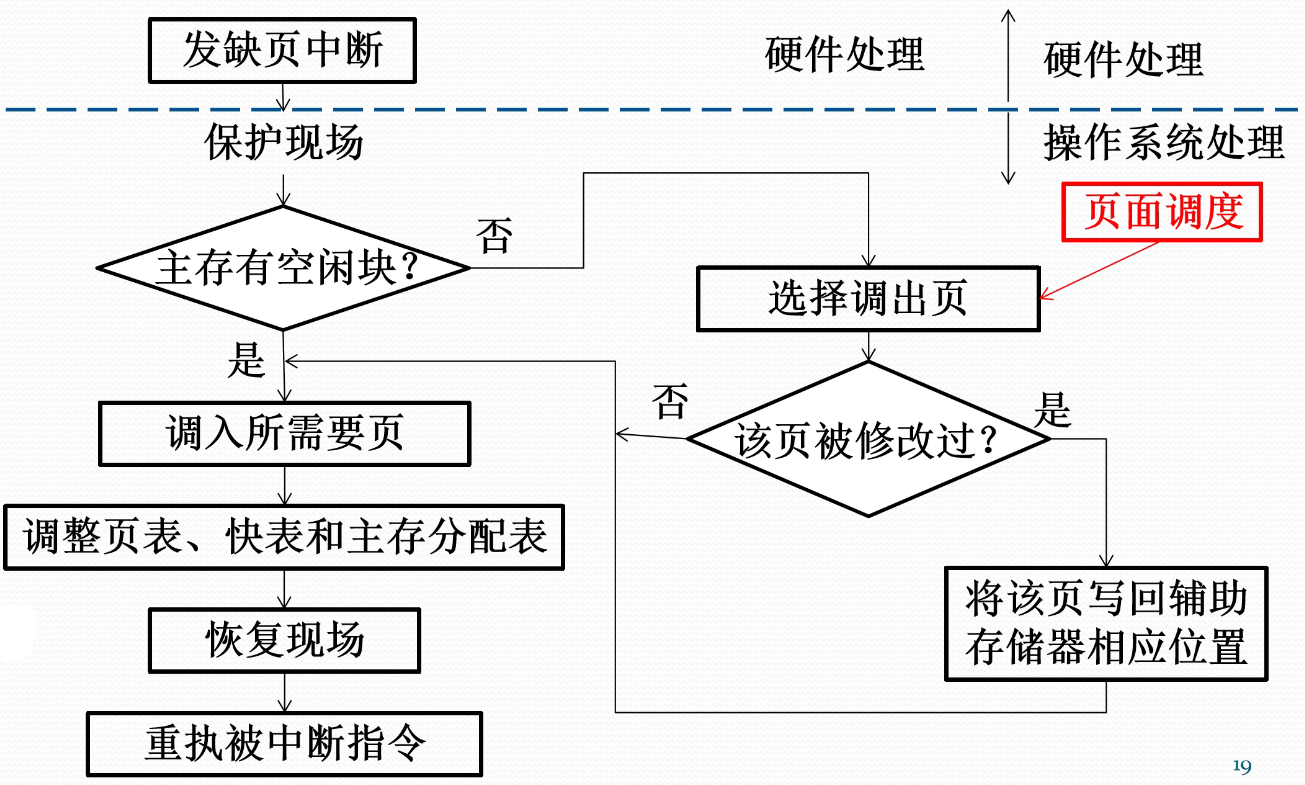
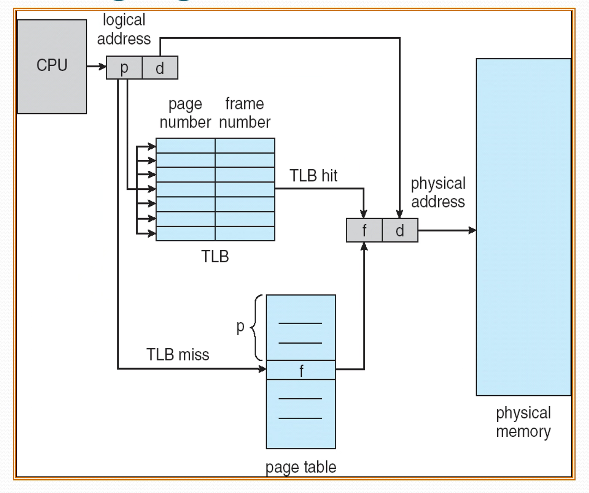
页式存储管理的快表
- 为提高地址转换速度,设置一个专用的高速存储器,用来存放页表的一部分
- 快表:存放在高速存储器中的页表部分
- 快表表项:页号,页架号
- 这种高速存储器是联想存储器,即按照内容寻址,而非按照地址访问
引入快表后的地址转换代价
- 采用快表后,可以加快地址转换速度
- 假定主存访问时间为200毫微秒,快表访问时间为40毫微秒,查快表的命中率是90%,平均地址转换代价为 (200+40)*90%+(200+200+40)*10%=260毫微秒
- 比两次访问主存的时间(400毫微秒)下降了35%
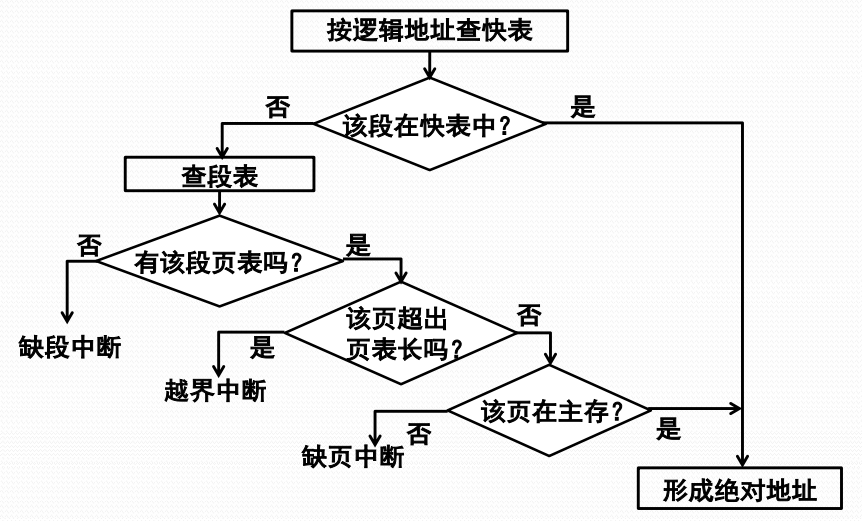
基于快表的地址转换流程
- 按逻辑地址中的页号查快表
- 若该页已在快表中,则由页架号和单元号形成绝对地址
- 若该页不在快表中,则再查主存页表形成绝对地址,同时将该页登记到快表中
- 当快表填满后,又要登记新页时,则需在快表中按一定策略淘汰一个旧登记项
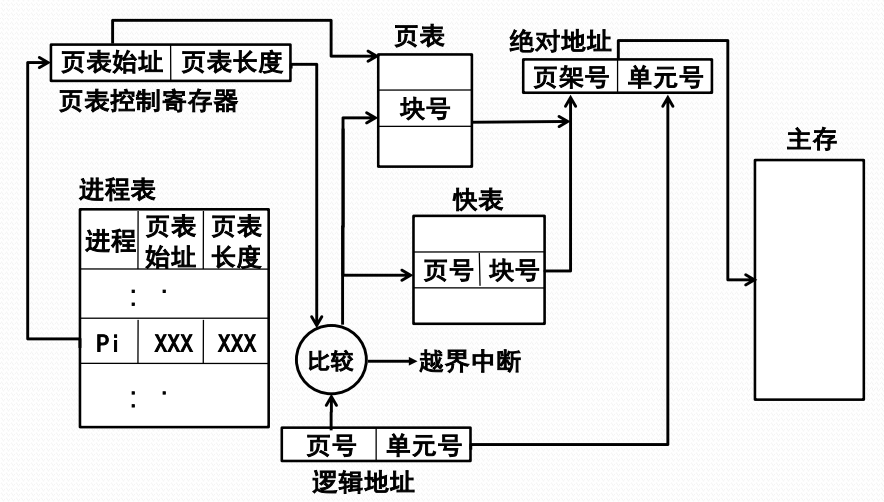
多道程序环境下的进程表
- 进程表中登记了每个进程的页表
- 进程占有处理器运行时,其页表起始地址和长度送入页表控制寄存器
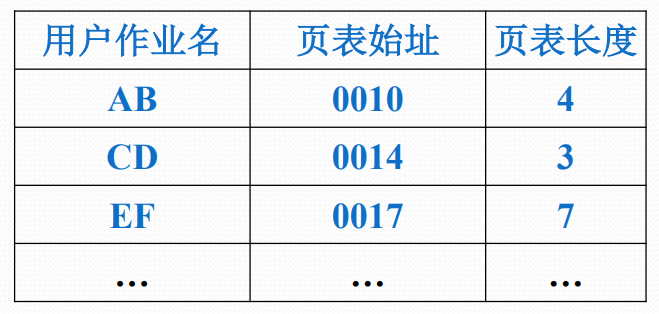
多道程序环境下的地址转换
3.3.3 页式虚拟存储管理
页式虚拟存储管理的基本思想
- 把进程全部页面装入虚拟存储器,执行时先把部分页面装入实际内存,然后,根据执行行为,动态调入不在主存的页,同时进行必要的页面调出
- 现代OS的主流存储管理技术
- 首次只把进程第一页信息装入主存,称为请求页式存储管理
页式虚拟存储管理的页表
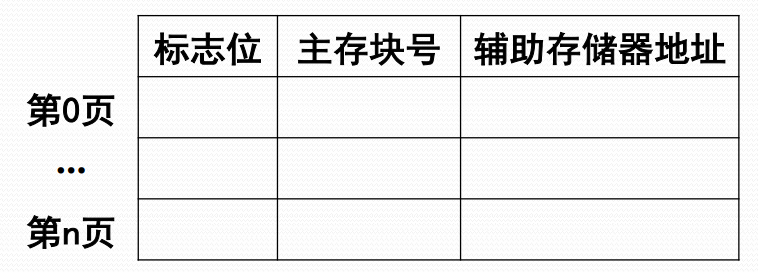
- 需要扩充页表项,指出:
- 每页的虚拟地址、实际地址
- 主存驻留标志、写回标志、保护标志、引用标志、可移动标志
页式虚拟存储管理的实现
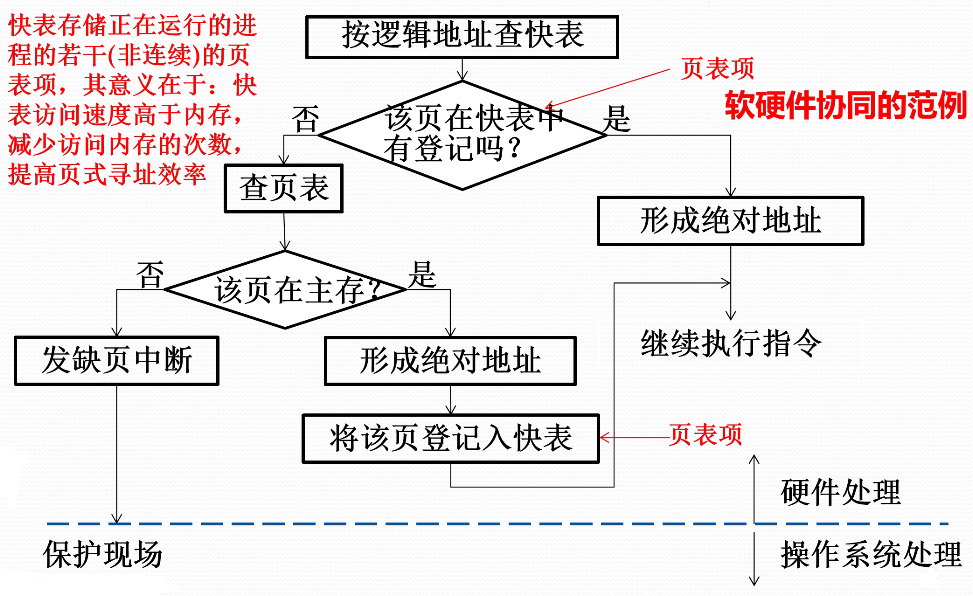
- CPU处理地址
- 若页驻留,则获得块号形成绝对地址
- 若页不在内存,则CPU发出缺页中断
- OS处理缺页中断
- 若有空闲页架,则根据辅存地址调入页,更新页表与快表等
- 若无空闲页架,则决定淘汰页,调出已修改页,调入页,更新页表与快表
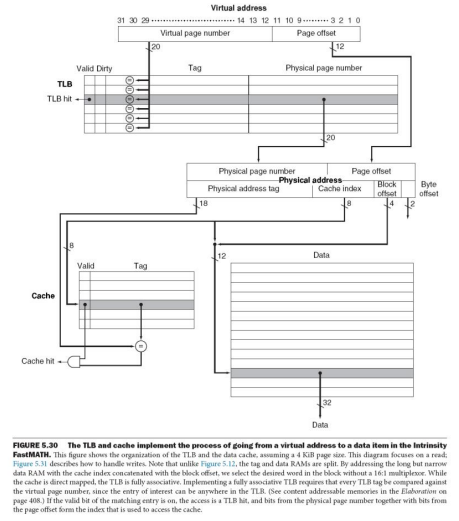
页式虚拟存储管理的地址转换
缺页中断的处理流程
补充:TLB(快表)
补充:Paging Hardware With TLB
3.3.4 页面调度
页面调度
- 当主存空间已满而又需要装入新页时,页式虚拟存储管理必须按照一定的算法把已在主存的一些页调出去
- 选择淘汰页的工作称为页面调度
- 选择淘汰页的算法称为页面调度算法
- 页面调度算法设计不当,会出现(刚被淘汰的页面立即又要调入,并如此反复)
- 这种现象称为抖动或颠簸
缺页中断率
- 假定进程P共 n 页,系统分配页架数 m 个
- P运行中成功访问次数为S,不成功访问次数为F,总访问次数 A=S+F
- 缺页中断率定义为:f=F/A
- 缺页中断率是衡量存储管理性能和用户编程水平的重要依据
影响缺页中断率的因素
- 分配给进程的页架数:可用页架数越多,则缺页中断率就越低
- 页面的大小:页面尺寸越大,则缺页中断率就越低
- 用户的程序编制方法:在大数据量情况下,对缺页中断率也有很大影响
用户编程的例子
- 程序将数组置为“0”,假定仅分得一个主存页架,页面尺寸为128个字,数组元素按行存放,开始时第一页在主存

OPT页面调度算法
- 理想的调度算法是:当要调入新页面时,首先淘汰以后不再访问的页,然后选择距现在最长时间后再访问的页
- 该算法由Belady出,称Belady算法,又称最佳算法(OPT)
- OPT只可模拟,不可实现
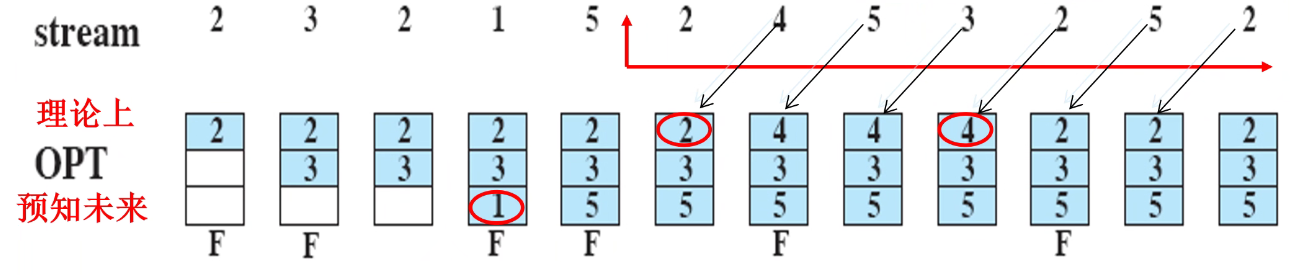
先进先出FIFO页面调度算法
- 总是淘汰最先调入主存的那一页,或者说主存驻留时间最长的那一页(常驻的除外)
- 模拟的是程序执行的顺序性,有一定合理性

最近最少用LRU页面调度算法
- 淘汰最近一段时间较久未被访问的那一页,即那些刚被使用过的页面,可能马上还要被使用到
- 模拟了程序执行的局部属性,既考虑了循环性又兼顾了顺序性
- 严格实现的代价大(需要维持特殊队列)

LRU算法的模拟实现
- 每页建一个引用标志,供硬件使用
- 设置一个时间间隔中断:中断时页引用标志置0
- 地址转换时,页引用标志置1
- 淘汰页面时,从页引用标志为0的页中间随机选择
- 时间间隔多长是个难点
最不常用LFU页面调度算法
- 淘汰最近一段时间内访问次数较少的页面,对OPT的模拟性比LRU更好
- 基于时间间隔中断,并给每一页设置一个计数器
- 时间间隔中断发生后,所有计数器清0
- 每访问页1次就给计数器加1
- 选择计数值最小的页面淘汰
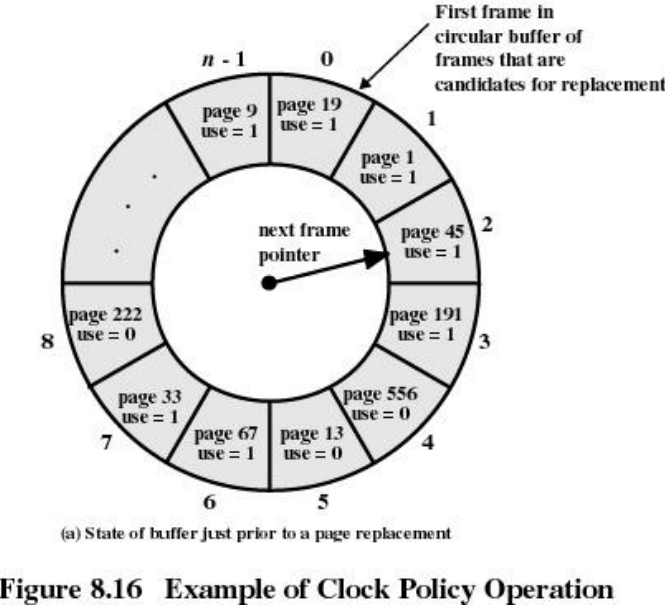
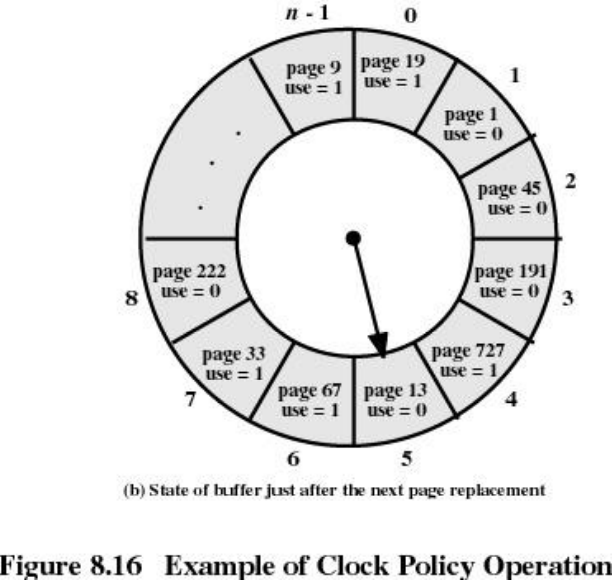
时钟CLOCK页面调度算法
- 采用循环队列机制构造页面队列,形成了一个类似于钟表面的环形表
- 队列指针则相当于钟表面上的表针,指向可能要淘汰的页面
- 使用页引用标志位
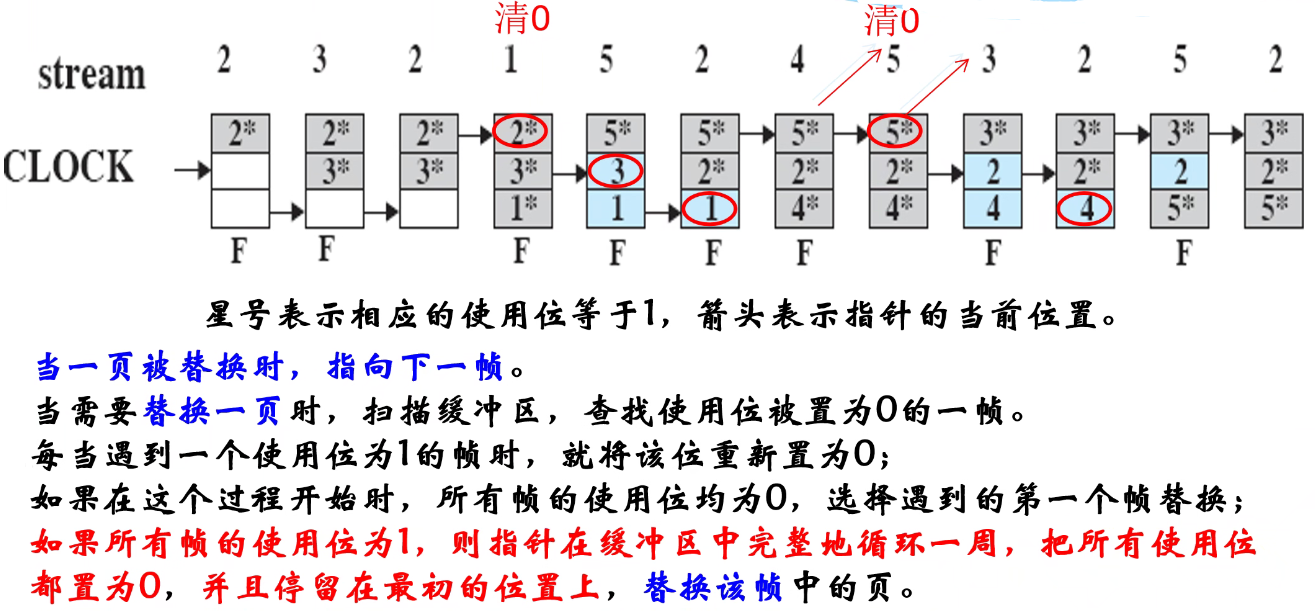
CLOCK算法的工作流程
- 页面调入主存时,其引用标志位置1
- 访问主存页面时,其引用标志位置1
- 淘汰页面时,从指针当前指向的页面开始扫描循环队列
- 把所遇到的引用标志位是1的页面的引用标志位清0,并跳过
- 把所遇到的引用标志位是0的页面淘汰,指针推进一步
3.3.5 反置页表(详见补充4)
反置页表的提出
- 页表及相关硬件机制在地址转换、存储保护、虚拟地址访问中发挥了关键作用
- 为页式存储管理设置专门硬件机构
- 内存管理单元MMU:CPU管理虚拟/物理存储器的控制线路,把虚拟地址映射为物理地址,并提供存储保护,必要时确定淘汰页面
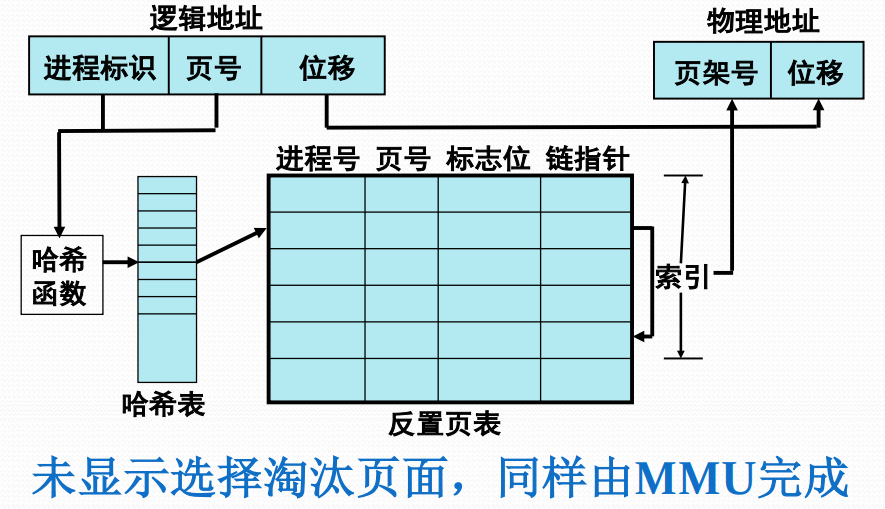
- 反置页表IPT:MMU用的数据结构
反置页表的基本思想
- 针对内存中的每个页架建立一个页表,按照块号排序
- 表项包含:正在访问该页框的进程标识、页号及特征位,和哈希链指针等
- 用来完成内存页架到访问进程页号的对应,即物理地址到逻辑地址的转换
反置页表的页表项
- 页号:虚拟地址页号
- 进程标志符:使用该页的进程号(页号和进程标志符结合起来标志一个特定进程的虚拟地址空间的一页)
- 标志位:有效、引用、修改、保护和锁定等标志信息
- 链指针:哈希链
基于反置页表的地址转换过程
- MMU通过哈希表把进程标识和虚页号转换成一个哈希值,指向IPT的一个表目
- MMU遍历哈希链找到所需进程的虚页号,该项的索引就是页架号,通过拼接位移便可生成物理地址
- 若遍历整个反置页表中未能找到匹配页表项,说明该页不在内存,产生缺页中断,请求操作系统调入
反置页表下的地址转换示意
3.4 段式存储管理
3.4.1 段式存储管理
段式程序设计
- 每个程序可由若干段组成,每一段都可以从“0”开始编址,段内的地址是连续的
- 分段存储器的逻辑地址由两部分组成
- 段号:单元号
程序的分段结构
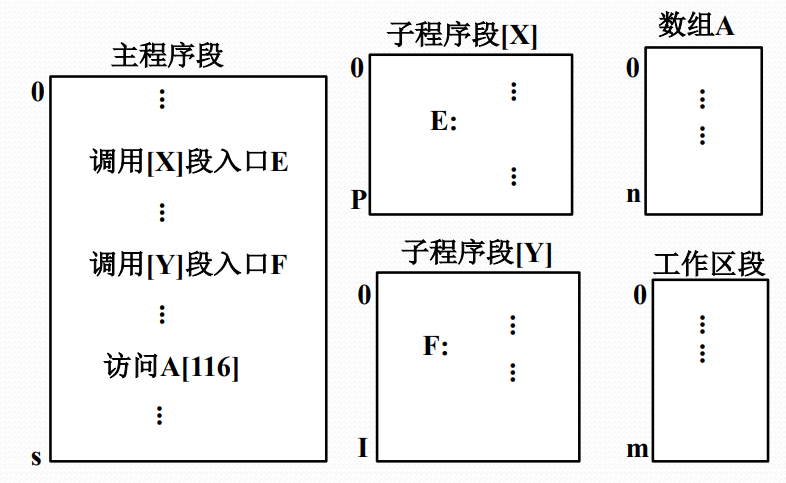
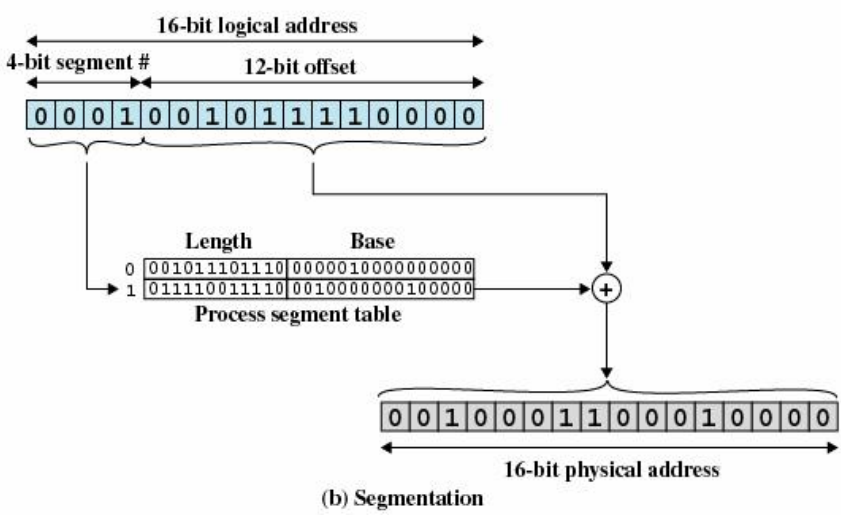
段式存储管理的基本思想
- 段式存储管理基于可变分区存储管理实现,一个进程要占用多个分区
- 硬件需要增加一组用户可见的段地址寄存器(代码段、数据段、堆栈段,附加段),供地址转换使用
- 存储管理需要增加设置一个段表,每个段占用一个段表项,包括:段始址、段限长,以及存储保护、可移动、可扩充等标志位
段式存储管理的地址转换流程
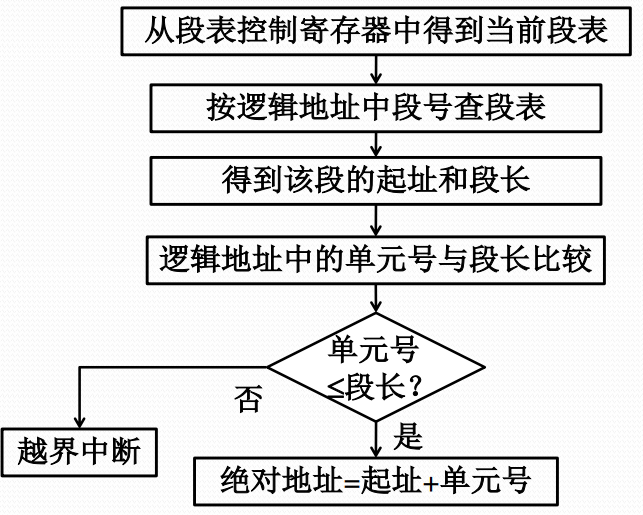
段的共享
- 通过不同进程段表中的项指向同一个段基址来实现
- 对共享段的信息必须进行保护,如规定只能读出不能写入,不满足保护条件则产生保护中断
3.4.2 段式虚拟存储管理
段式虚拟存储管理的基本思想
- 把进程的所有分段都存放在辅存中,进程运行时先把当前需要的一段或几段装入主存,在执行过程中访问到不在主存的段时再把它们动态装入
- 段式虚拟存储管理中段的调进调出是由OS自动实现的,对用户透明
- 与段覆盖技术不同,它是用户控制的主存扩充技术,OS不感知
段式虚拟存储管理的段表扩充
- 段表的扩充
- 特征位: 00(不在内存)01(在内存)11(共享段)
- 存取权限: 00(可执行)01(可读)11(可写)
- 扩充位: 0(固定长)1(可扩充)
- 标志位: 00(未修改)01(已修改)11(不可移动)
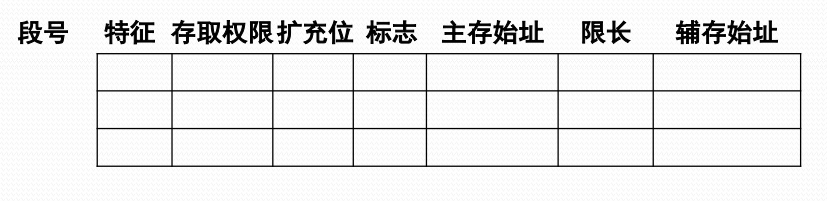
段式虚拟存储管理的地址转换
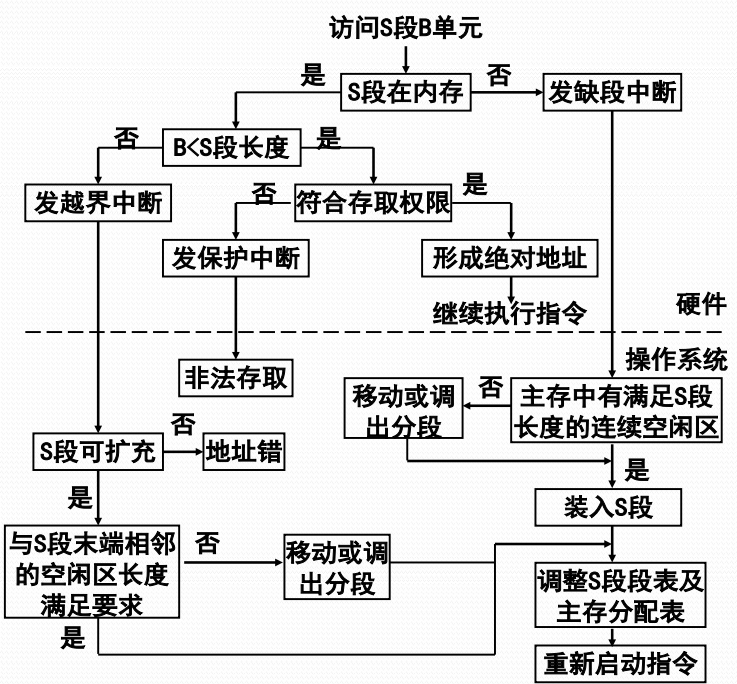
3.4.3 段页式存储管理
段页式存储管理的基本思想
- 段式存储管理可以基于页式存储管理实现
- 每一段不必占据连续的存储空间,可存放在不连续的主存页架中
- 能够扩充为段页式虚拟存储管理
- 装入部分段,或者装入段中部分页面
段页式存储管理的段表和页表
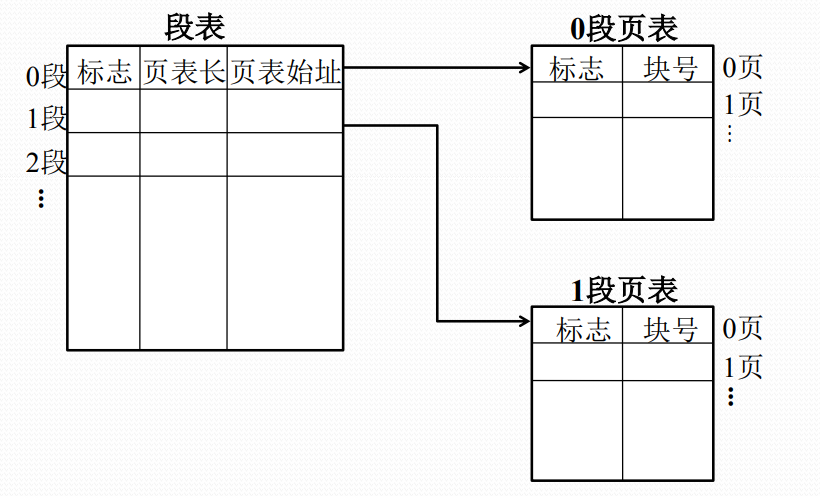
段页式存储管理的地址转换

段页式虚拟存储管理的地址转换
补充内容
补充1:虚拟存储器的概念(补充局部性特征)
抖动
- 如果一块正好将要被用到之前扔出,操作系统有不得不很快把它取回来,太多的这类操作会导致一种称为系统抖动的情况
- 在处理缺页中断期间,处理器的大部分时间都用于交换块,而不是用户进程的执行指令
程序局部性原理(1)
- 指程序在执行过程中的一个较短时间内,所执行的指令地址或操作数地址分别局限于一定的存储区域中。又可细分时间局部性和空间局部性
- 早在1968年P. Denning研究程序执行时的局部性原理,对此进行研究的还有Knuth(分析一组学生的Fortran程序)、Tanenbaum (分析操作系统的过程)、Huck(分析通用科学计算程序),发现程序和数据的访问都有聚集成群的倾向
- 某存储单元被使用,其相邻存储单元很快也被使用(称空间局部性spatial locality)
- 或者最近访问过的程序代码和数据,很快又被访问(称时间局部性temporal locality)
分页下的运行情况
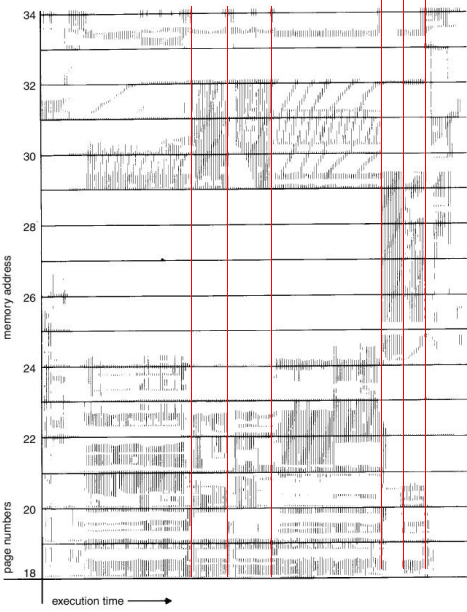
程序局部性原理(2)
- 程序中只有少量分支和过程调用,存在很多顺序执行的指令
- 程序含有若干循环结构,由少量代码组成,而被多次执行
- 过程调用的深度限制在小范围内,因而,指令引用通常被局限在少量过程中
- 涉及数组、记录之类的数据结构,对它们的连续引用是对位置相邻的数据项的操作
- 程序中有些部分彼此互斥,不是每次运行时都用到
程序局部性原理(3)
经验与分析表明,程序具有局部性,进程执行时没有必要把全部信息调入主存,只需装入一部分的假设是合理的,部分装入的情况下,只要调度得当,不仅可正确运行,而且能在主存中放置更多进程,充分利用处理器和存储空间
虚拟内存的技术需要
- 必须有对所采用的分页或分段方案的硬件支持
- 操作系统必须有管理页或者段在主存和辅助存储器之间移动的软件。
补充2:伙伴系统
伙伴系统
伙伴系统(Knuth,1973),又称buddy算法,是一种固定分区和可变分区折中的主存管理算法,基本原理是:任何尺寸为$2^{i}$的空闲块都可被分为两个尺寸为$2^{i-1}$的空闲块,这两个空闲块称作伙伴,它们可以被合并成尺寸为$2^{i}$的原先空闲块。
伙伴通过对大块的物理主存划分而获得
假如从第0个页面开始到第3个页面结束的主存

每次都对半划分,那么第一次划分获得大小为2页的伙伴,如0、1和2、3
进一步划分,可以获得大小为1页的伙伴,例如0和1,2和3
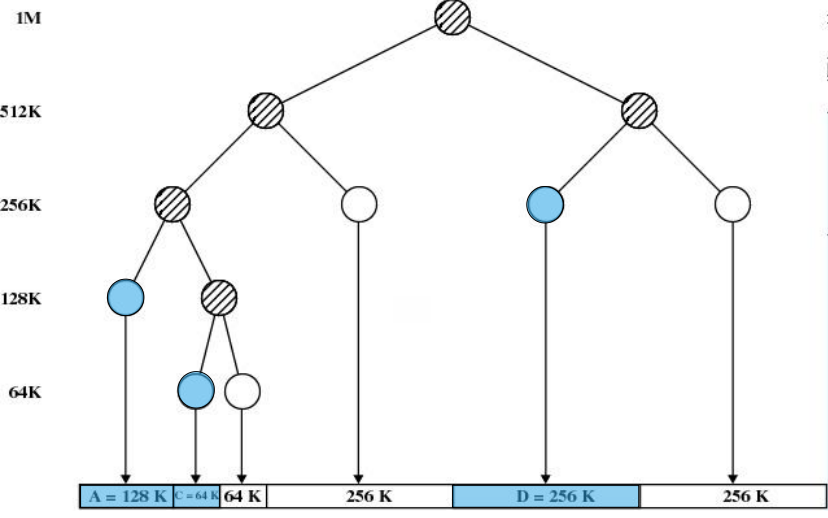
Linux伙伴系统
- 以page结构为数组元素的mem_map[]数组
- 以free_area_struct结构为数组元素的free_area数组
- 位图数组(bitmap)
Linux基于伙伴的slab分配器
为什么要使用slab分配器?
- 伙伴系统以页框为基本分配单位,内核在很多情况下,需要的主存量远远小于页框大小,如inode、vma、task_struct等,为了更经济地使用内核主存资源,引入SunOS操作系统中首创的基于伙伴系统的slab分配器,其基本思想是:为经常使用的小对象建立缓存,小对象的申请与释放都通过slab分配器来管理,仅当缓存不够用时才向伙伴系统申请更多空间。//页内可以按2的幂次拆分。
- 优点:充分利用主存,减少内部碎片,对象管理局部化,尽可能少地与伙伴系统打交道,从而提高效率。
slab的结构
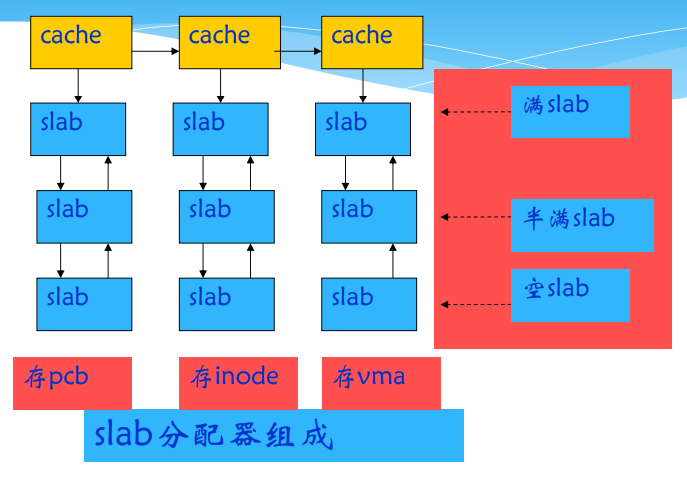
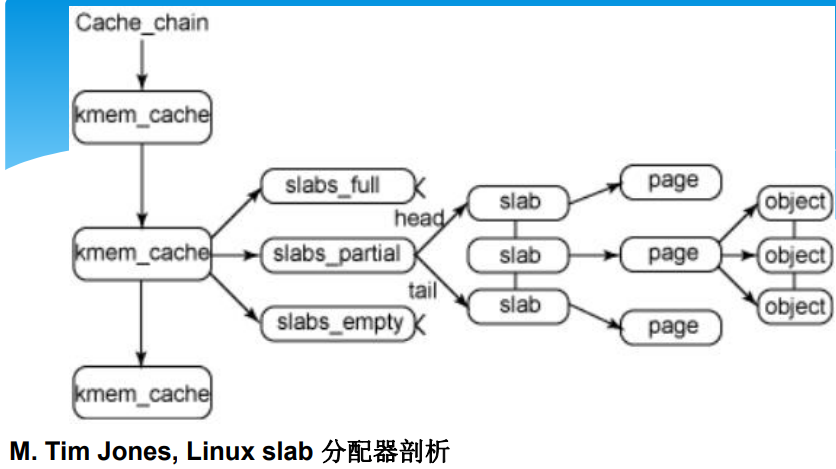
- https://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/
- Linux还提供十三种通用缓存,其存储对象的大小分别为32B、64B、128B、256B、512B、1KB、2KB、4KB、8KB、16KB、32KB、64KB和128KB,这些缓存用来满足特定对象之外的普通主存需求,单位的大小呈2的幂数增长,保证内部碎片率不超过50%。
slab举例
例子task_struct slab
- 内核用全局变量存放指向task_struct slab的指针:kmem_struct_t *task_struct_cachep;初始化时,在fork_init()中调用kmem_cache_create()函数创建高速缓存,存放类型为task_struct的对象。
- 每当进程调用fork()时,调用内核函数do_fork(),它再使用kmem_cache_alloc()函数在对应slab中建立一个task_struct对象。
- 进程执行结束后,task_struct对象被释放,返还给task_struct_cachep slab
slab分配器主要操作
- kmem_cache_create()函数:创建专用cache,规定对象的大小和slab的构成,并加入cache管理队列;
- kmem_cache_alloc()与kmem_cache_free()函数:分别用于分配和释放一个拥有专用slab队列的对象;
- kmem_cache_grow()与kmem_cache_reap()函数:kmem_cache_grow()它向伙伴系统申请向cache增加一个slab;kmem_cache_reap()用于定时回收空闲slab;
- kmem_cache_destroy()与kmem_cache_shrink():用于cache的销毁和收缩;
- kmalloc()与kfree()函数:用来从通用的缓冲区队列中申请和释放空间;
- kmem_getpages()与kmem_freepages()函数:slab与页框级分配器的接口,当slab分配器要创建新的slab或cache时,通过kmem_getpages()向内核提供的伙伴算法来获得一组连续页框。如果释放分配给slab分配器的页框,则调用kmem_freepages()函数。
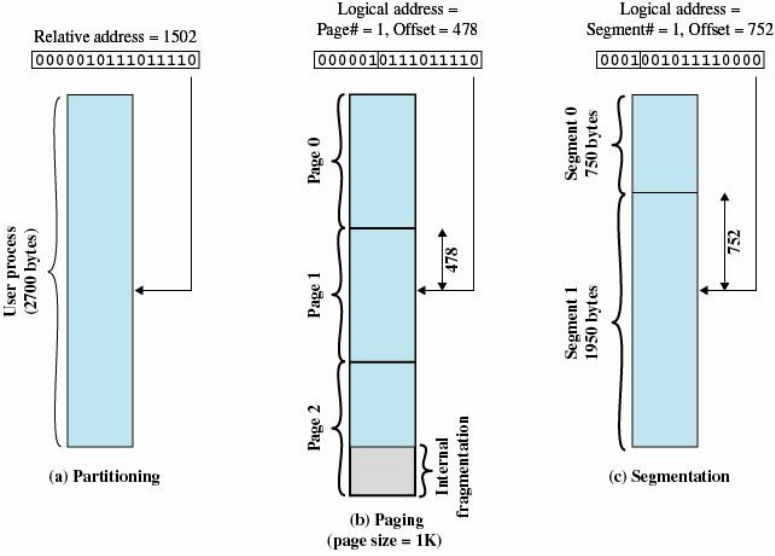
补充3:分段和分页的寻址计算
分段
- 采用分段法
- 某个分段的逻辑地址的段号为2, 段内偏移量为100, 计算它的物理地址
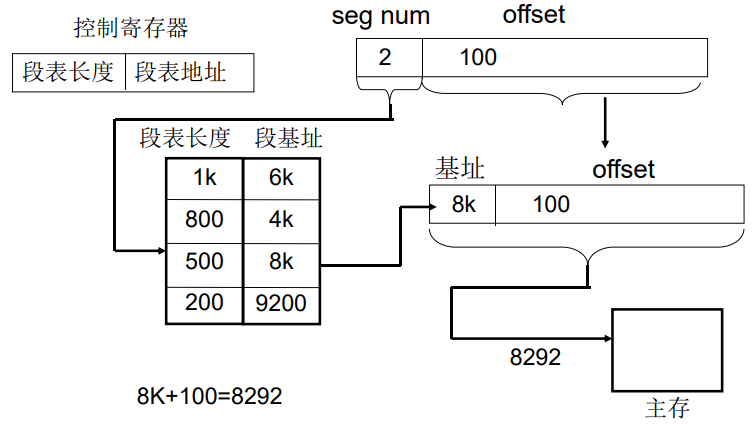
分页和分段的比较
- 分段
- 分段是信息的逻辑单位,由源程序的逻辑结构所决定,用户可见
- 长可根据用户需要来规定,段起始地址可从任何主存地址开始。
- 分段方式中,源程序(段号,段内位移)经连结装配后地址仍保持二维结构。
- 分页
- 分页是信息的物理单位,与源程序的逻辑结构无关,用户不可见
- 页长由系统确定,页面只能以页大小的整倍数地址开始
- 分页方式中,源程序(页号,页内位移)经连结装配后地址变成了一维结构
分页:逻辑地址->物理地址
分页:
分段:
分页地址转换
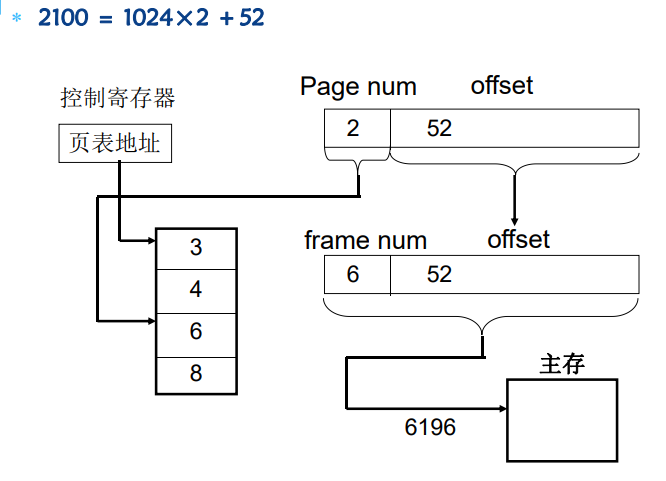
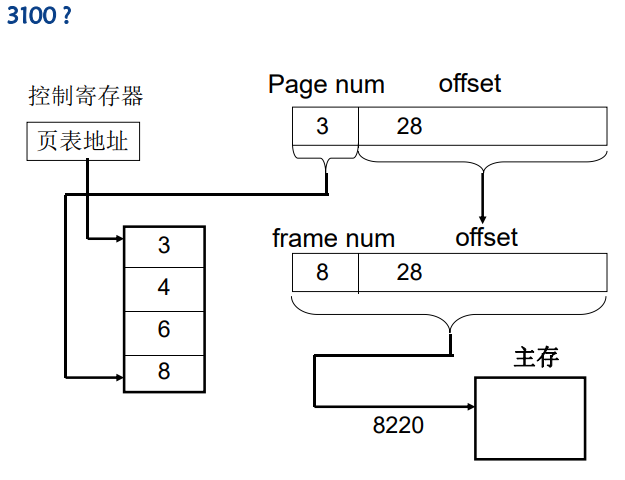
- 页面与页框的大小为1024字节, 指令 MOV 2100, 3100
- 求MOV指令中两个操作数的物理地址
补充4:多级页表与反置页表
4.1 多级页表
背景
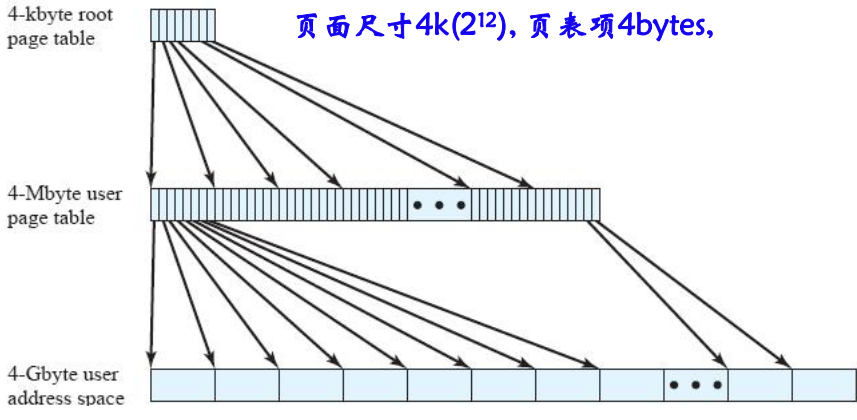
现代计算机普遍支持$2^{32}~2^{64}$容量的逻辑地址空间,采用分页存储管理时,页表相当大,以Windows为例,其运行的Intel x86平台具有32位地址,规定页面4KB($2^{12}$)时,那么,4GB($2^{32}$)的逻辑地址空间由1兆($2^{20}$)个页组成,若每个页表项占用4个字节,则需要占用4MB($2^{22}$)连续主存空间存放页表。系统中有许多进程,因此页表存储开销很大。
多级页表的概念
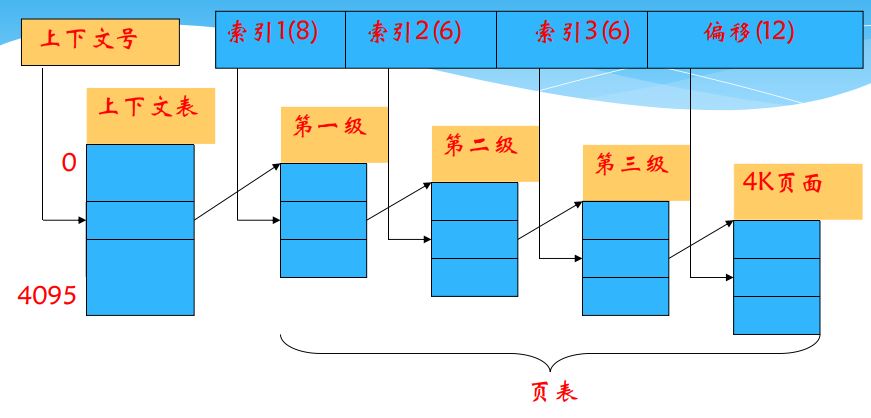
- 系统为每个进程建一张页目录表,它的每个表项对应一个页表页,而页表页的每个表项给出了页面和页框的对应关系,页目录表是一级页表,页表页是二级页表。
- 逻辑地址结构有三部分组成:页目录、页表页和位移
两级页表(32位地址)
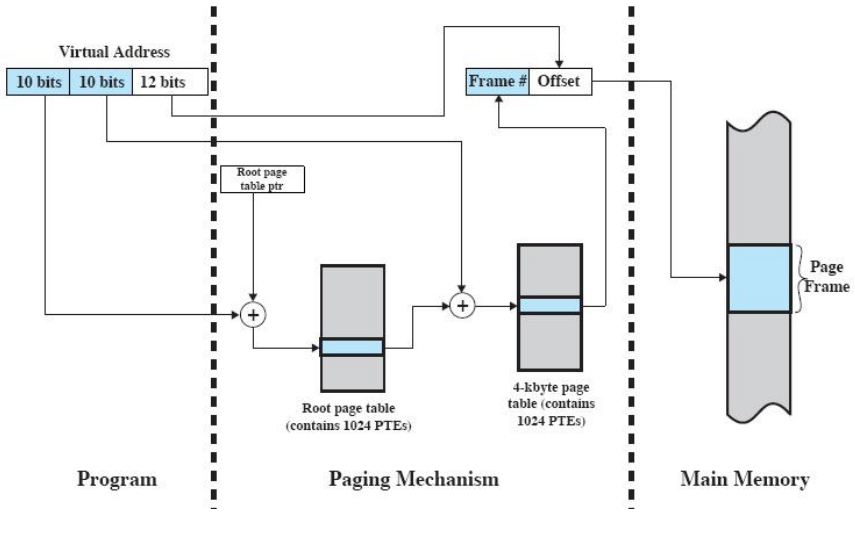
多级页表的地址转换过程

二级页表
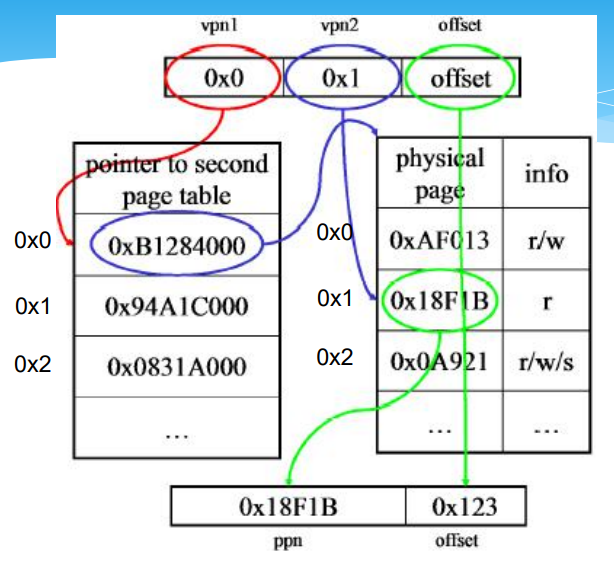
SUN SPARC计算机三级分页结构
- 问题:增加了寻址时间,在计算机系统中时间与空间总是存在一些矛盾,因此经常会采取折中的方案,以时间换空间,或者以空间换取时间。
多级页表的本质
- 多级不连续导致多级索引。
- 以二级页表为例,用户程序的页面不连续存放,要有页面地址索引,该索引是进程页表;进程页表又是不连续存放的多个页表页,故页表页也要页表页地址索引,该索引就是页目录。
- 页目录项是页表页的索引,而页表页项是进程程序的页面索引。
4.2 反置页表(Inverted Page Table)
概念
- 页表设计的一个重要缺陷是页表的大小与虚拟地址空间的大小成正比
- 在反向页表方法中,虚拟地址的页号部分使用一个简单散列函数映射到哈希表中。哈希表包含一个指向反向表的指针,而反向表中含有页表项。
- 通过这个结构,哈希表和反向表中只有一项对应于一个实存页(面向实存),而不是虚拟页(面向虚存)。
- 因此,不论有多少进程、支持多少虚拟页,页表都只需要实存中的一个固定部分。
- 用于PowerPC, UltraSPARC, IA-64架构
组成
- 页号:虚拟地址页号部分。
- 进程标志符:使用该页的进程。页号和进程标志符结合起来标志一个特定的进程的虚拟地址空间的一页。
- 控制位:该域包含一些标记,比如有效、访问和修改,以及保护和锁定的信息。
- 链指针:如果某个项没有链项,则该域为空(允许用一个单独的位来表示)。
线性反置页表的结构
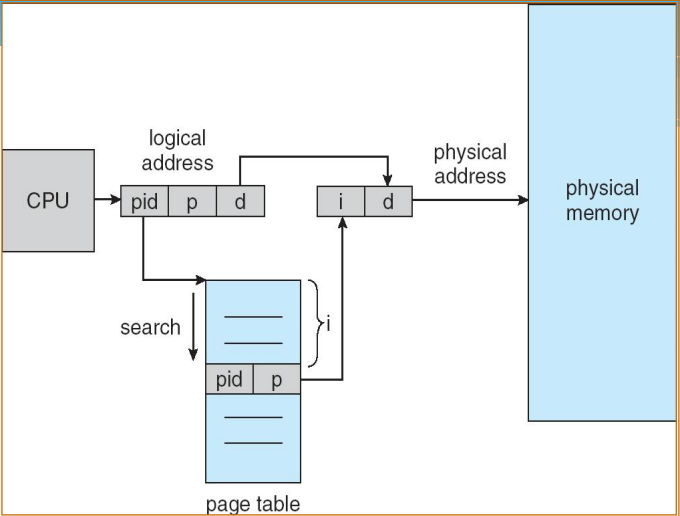
- 问题:线性查找,效率低,有可能遍历完才发现缺页中断
改进(引入hash)
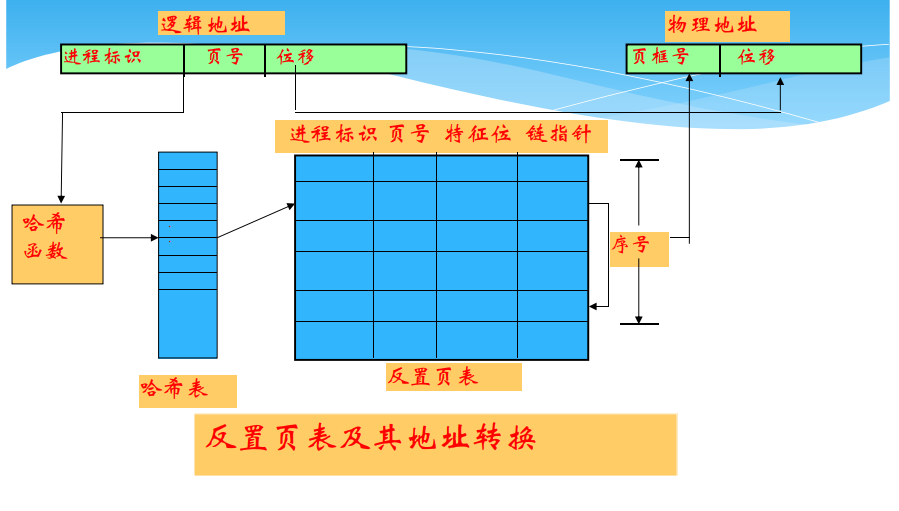
反置页表地址转换过程
逻辑地址给出进程标识和页号,用它们去比较IPT,若整个反置页表中未能找到匹配的页表项,说明该页不在主存,产生缺页中断,请求操作系统调入;否则,该表项的序号便是页框号,块号加上位移,便形成物理地址。
线性反置页表
pid是隐含的
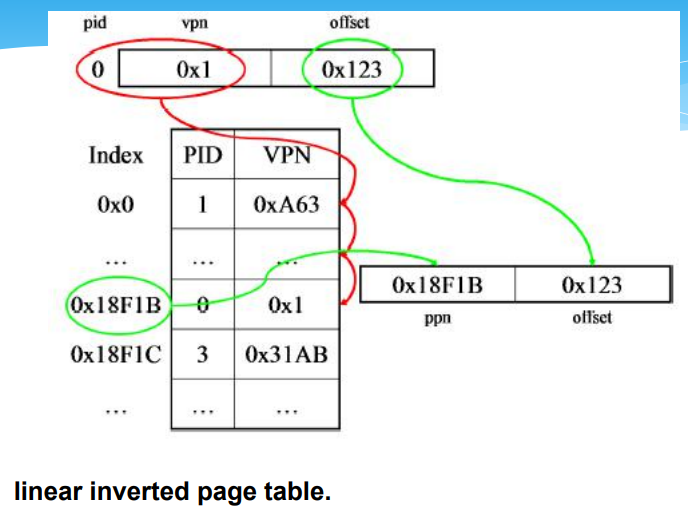
哈希线性反置页表
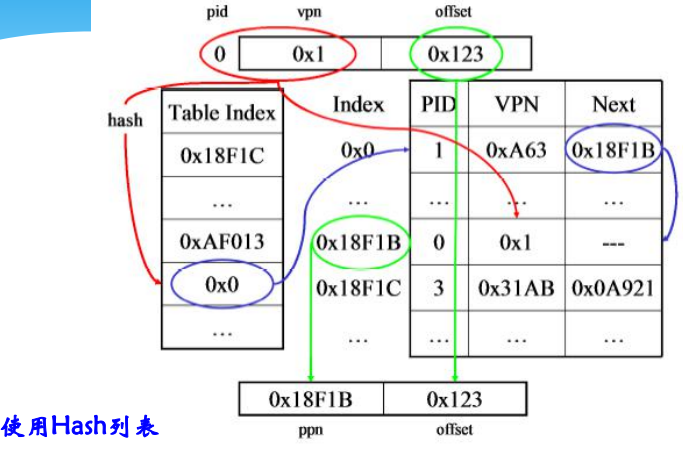
页表的结构称为“反向”是因为它使用帧号而不是虚拟页号来索引页表项
主存分配的位示图和链表方法
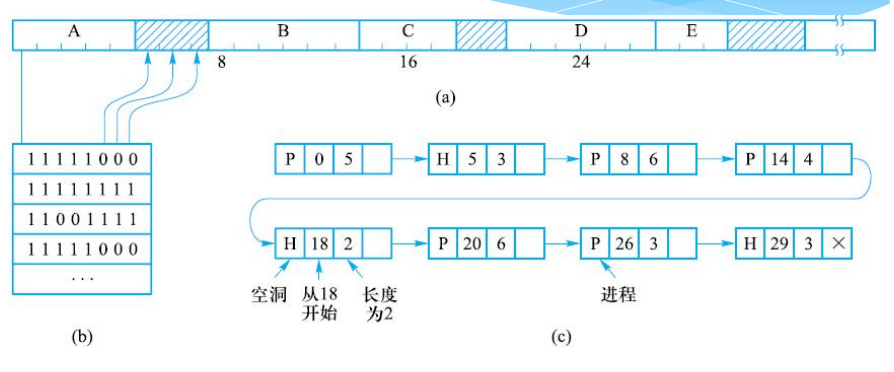
段页式存储管理

补充5:页的大小设计
- 页越小, 内存碎片越少
- 页越小, 每个进程需要页数越多
- 每个进程的页越多就意味着页表更大,而页表大意味着在虚拟内存中占据更多的空间
- 辅存设计用于有效传输大数据块,因此页面大小越大越好
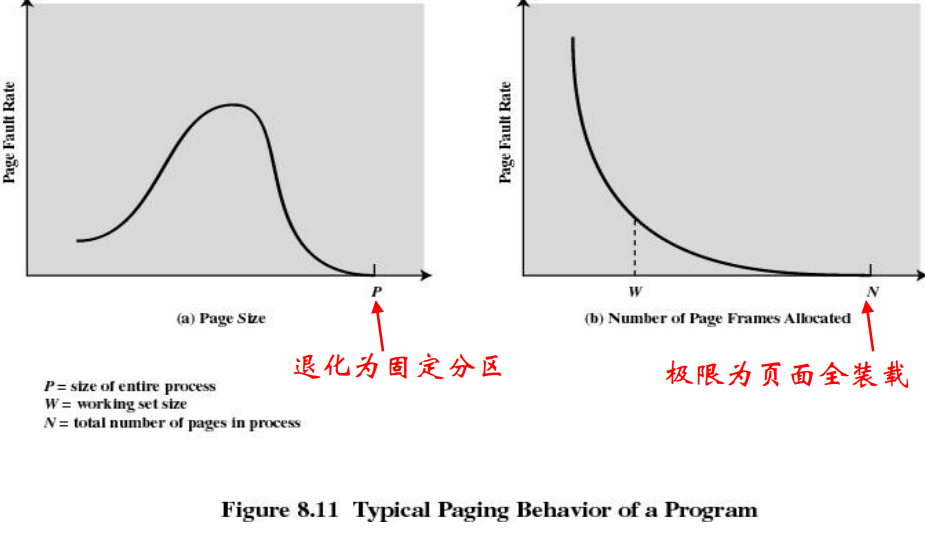
- 多种页面大小提供了有效使用TLB所需的灵活性
- 大多数操作系统只支持一种页面大小
补充6:页面替换算法
OPT、FIFO、LRU、CLOCK算法见3.3.4
CLOCK
Belady’s Anomaly(Belady异常)
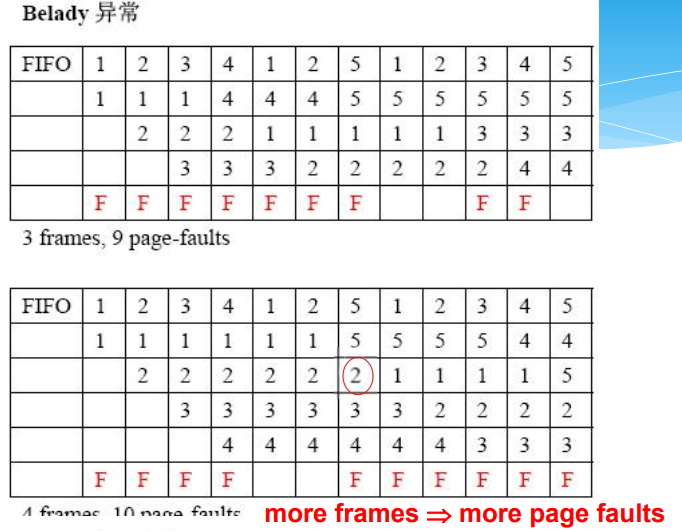
FIFO算法的Belady异常
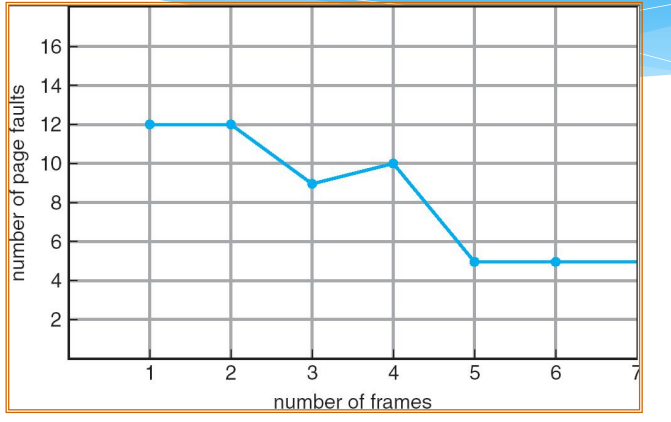
Comparison of Placement Algorithms
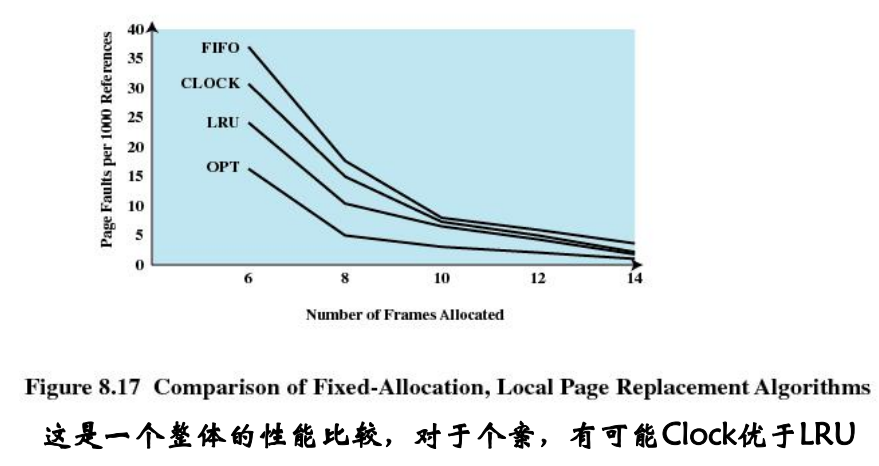
Basic Replacement Algorithms
- Page Buffering
- Replaced page is added to one of two lists
- free page list if page has not been modified
- modified page list
- Replaced page remains in memory
- If referenced again, it is returned at little cost
- Modified pages are written out in cluster
- Replaced page is added to one of two lists
Resident Set Size(驻留集规模)
- Fixed-allocation
- gives a process a fixed number of pages within which to execute
- when a page fault occurs, one of the pages of that process must be replaced
- Variable-allocation
- number of pages allocated to a process varies over the lifetime of the process
Fixed Allocation, Local Scope
- Number of frames allocated to process is fixed
- Page to be replaced is chosen from among the frames allocated to the process
Variable Allocation, Global Scope
- Number of frames allocated to process is variable
- Page to be replaced is chosen from all frames
- Easiest to implement
- Adopted by many operating systems
- Operating system keeps list of free frames
- Free frame is added to resident set of process when a page fault occurs
Variable Allocation, Local Scope
- Number of frames allocated to process is variable
- Page to be replaced is chosen from among the frames allocated to the process
- When new process added, allocate number of page frames based on application type, program request, or other criteria
- When page fault occurs, select page from among the resident set of the process that suffers the fault
- Reevaluate allocation from time to time
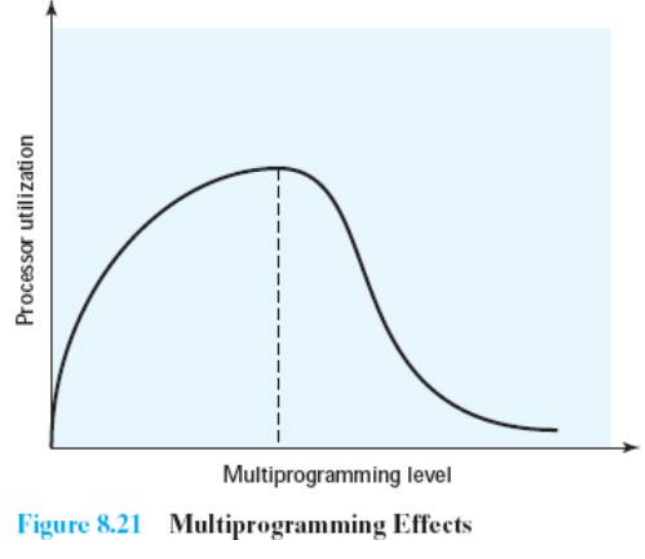
根据页面置换算法可借用的外界条件,将页面置换算法分为:
局部页面置换算法:置换页面的选择范围仅限于当前进程占用的内存页面
全局页面置换算法:置换页面的选择范围是所有可换出的内存页面(并不是所有的内存页面都可以换出内存,比如内核关键代码所在内存页面;因此对这些页面,会将其页表项的锁定位置1,从而操作系统在换出内存页面时就不会考虑这些页面)。
局部页面替换算法
- 局部最佳页面替换算法
- 工作集模型和工作集置换算法
局部最佳页面替换算法
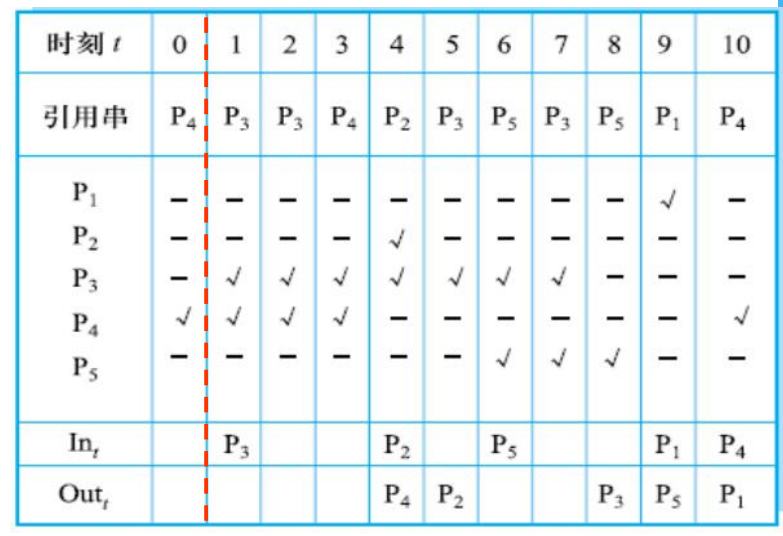
- 1976年Prieve提出一种局部最佳页面替换算法MIN(Local Minimum),它与全局最佳替换算法类似,需事先知道程序的页面引用串,再根据进程行为改变驻留页面数量
- 实现思想:进程在时刻 t 访问某页面,如果该页面不在主存中,导致一次缺页,把该页面装入一个空闲页框
不论发生缺页与否,算法在每一步要考虑引用串,如果该页面在时间间隔(t, t+τ)内未被再次引用,那么就移出;否则,该页被保留在进程驻留集中 (看未来)
τ为一个系统常量,间隔(t, t+τ)称作滑动窗口。例子中τ=3
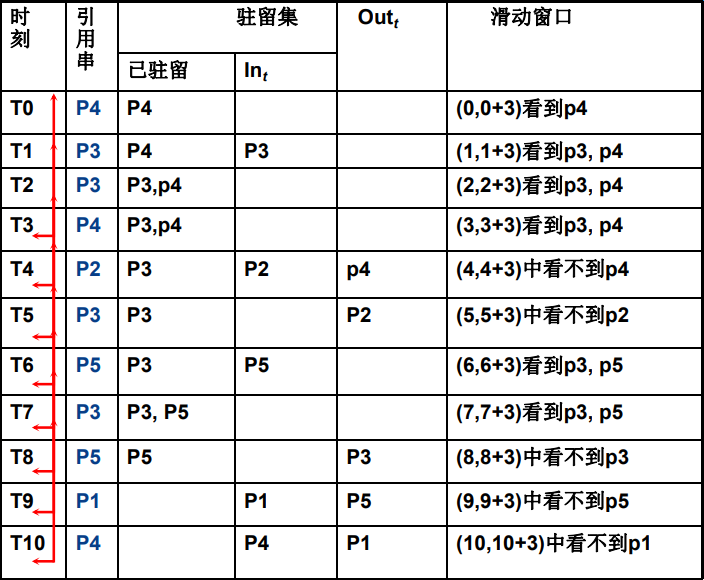
缺页总数为5次,驻留集大小在1-2之间变化,任何时刻至多两个页框被占用,通过增加τ值,缺页数目可减少,但代价是花费更多页框。
工作集模型和工作集置换算法
- 进程工作集指“在某一段时间间隔内进程运行所需访问的页面集合”
- 实现思想:工作集模型用来对局部最佳页面替换算法进行模拟实现,不向前查看页面引用串,而是基于程序局部性原理向后看
- 任何给定时刻,进程不久的将来所需主存页框数,可通过考查其过去最近的时间内的主存需求做出估计
进程工作集
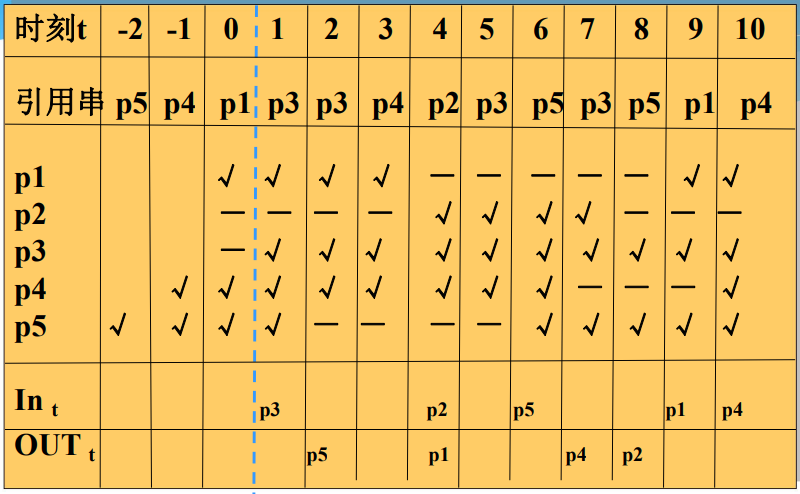
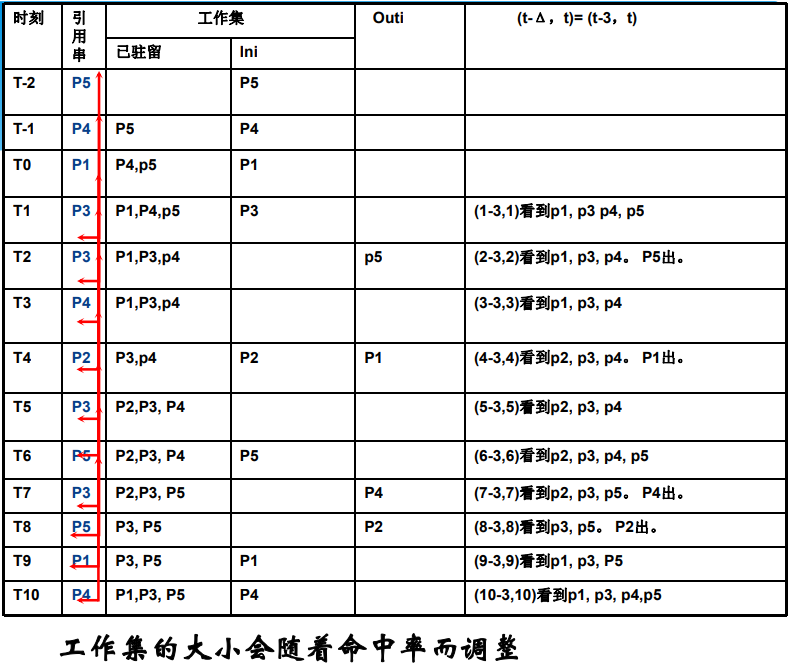
- 指“在某一段时间间隔内进程运行所需访问的页面集合”,W(t,Δ)表示在时刻 t-Δ 到时刻 t 之间( (t-Δ,t))所访问的页面集合,进程在时刻 t 的工作集
Δ 是系统定义的一个常量。变量 Δ 称为“工作集窗口尺寸”,可通过窗口来观察进程行为,还把工作集中所包含的页面数目称为“工作集尺寸”
Δ=3
Working-set model
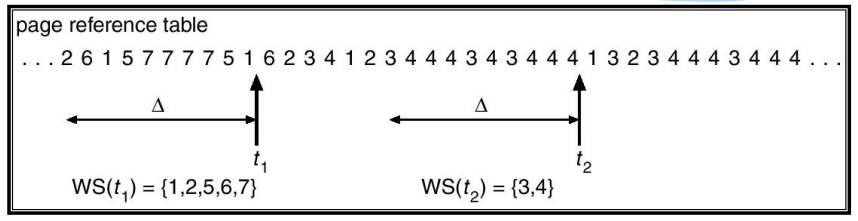
工作集替换示例
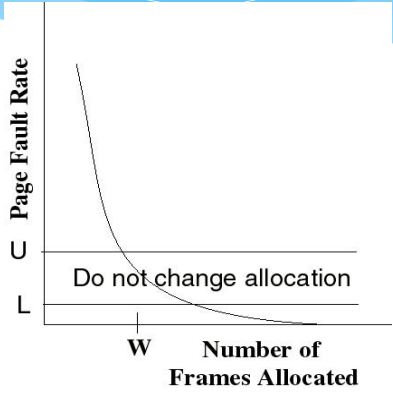
The Page-Fault Frequency Strategy
- Define an upper bound U and lower bound L for page fault rates
- Allocate more frames to a process if fault rate is higher than U
- Allocate less frames if fault rate is < L
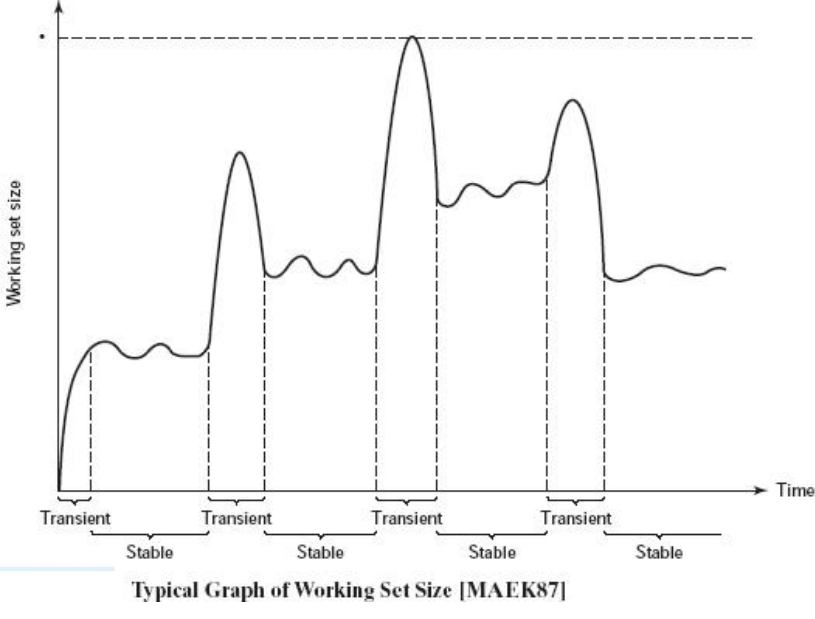
- The resident set size should be close to the working set size W
- We suspend the process if the PFF > U and no more free frames are available
通过工作集确定驻留集大小
- 监视每个进程的工作集,只有属于工作集的页面才能留在主存;
- 定期地从进程驻留集中删去那些不在工作集中的页面;
- 仅当一个进程的工作集在主存时,进程才能执行。
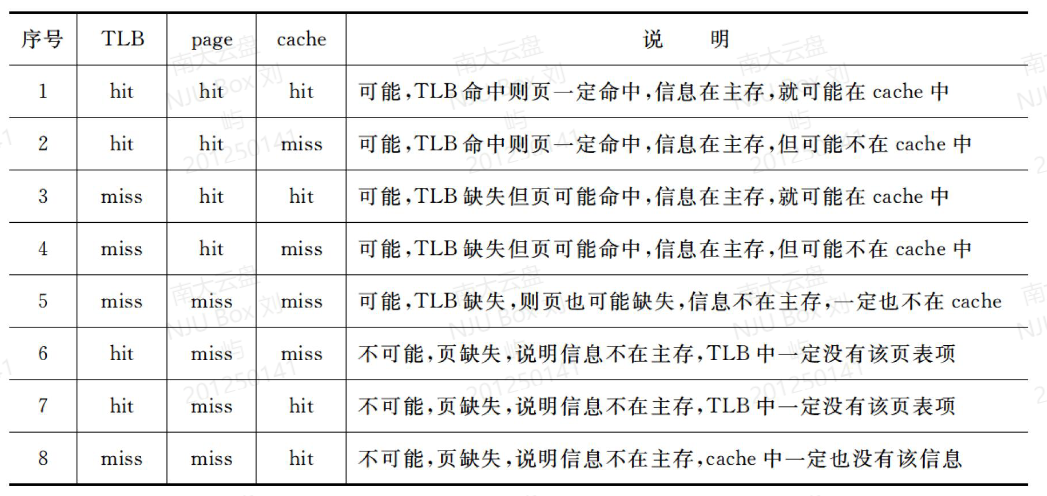
补充7:TLB快表,页表,缺页