语义分析
本节课代码见https://github.com/courses-at-nju-by-hfwei/2022-compilers-coding
一、类型系统与类型检查
1. 类型系统

1.1 JS 糟糕的类型系统

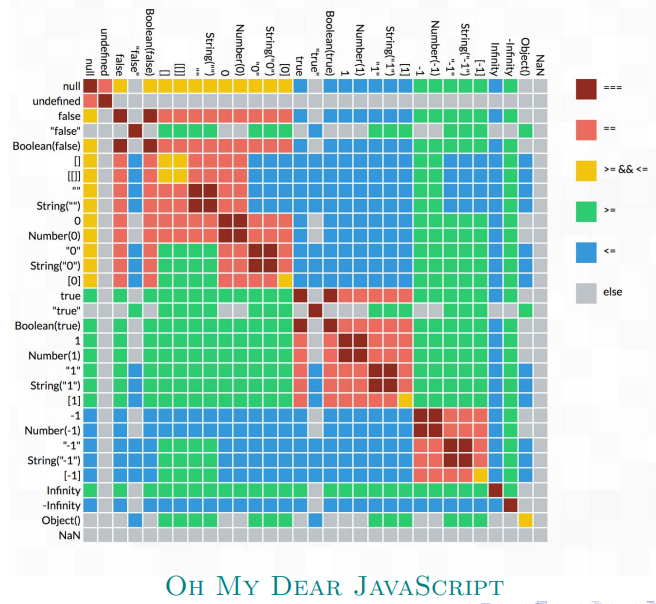
2. 类型检查
2.1 类型检查

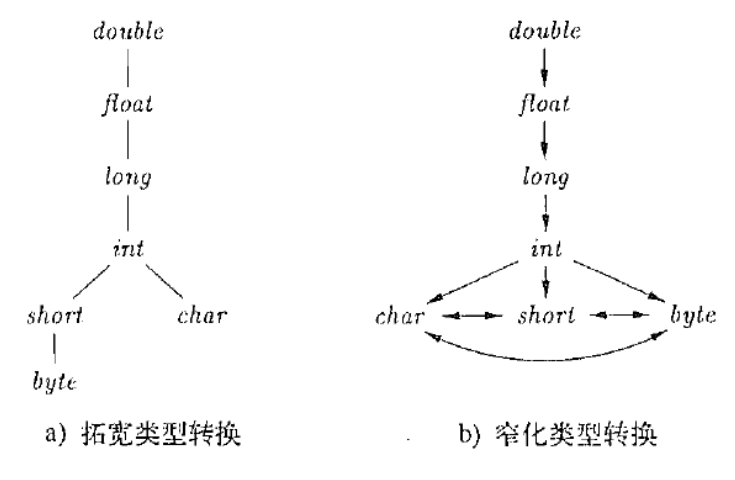
2.2 类型转换
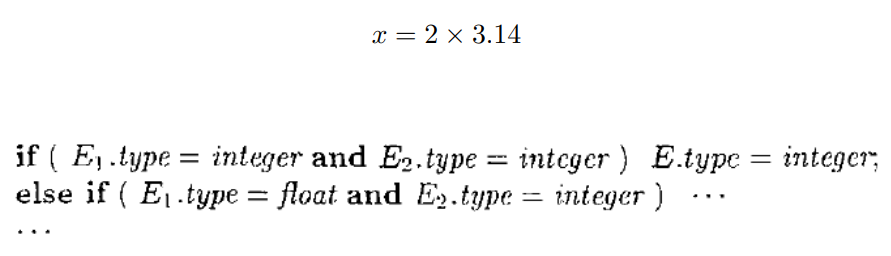
不要写这样的代码!!!
2.3 类型综合
根据子表达式的类型确定表达式的类型

2.4 类型推导
根据某语言结构的使用方式确定表达式的类型

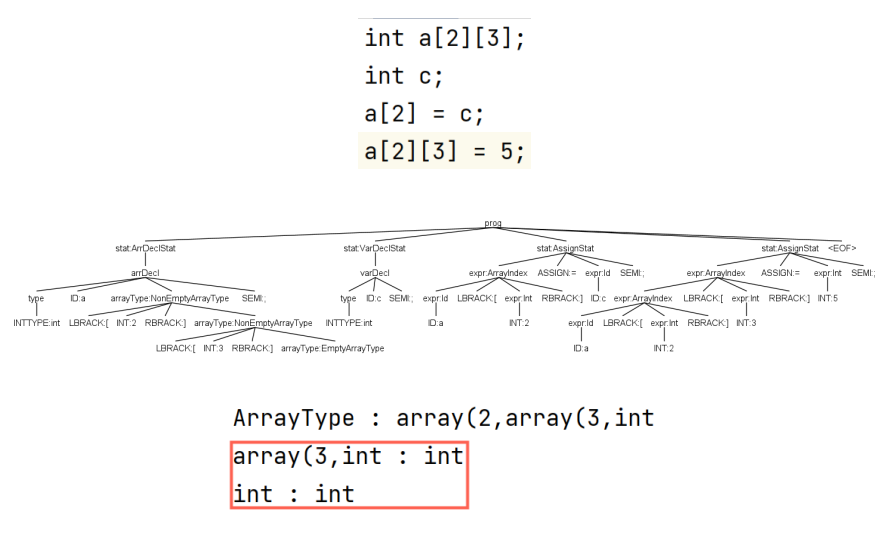
3. 数组类型文法
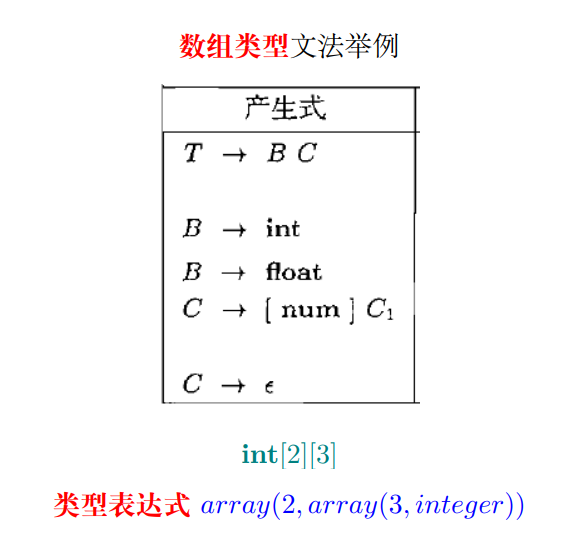
3.1 语法分析树
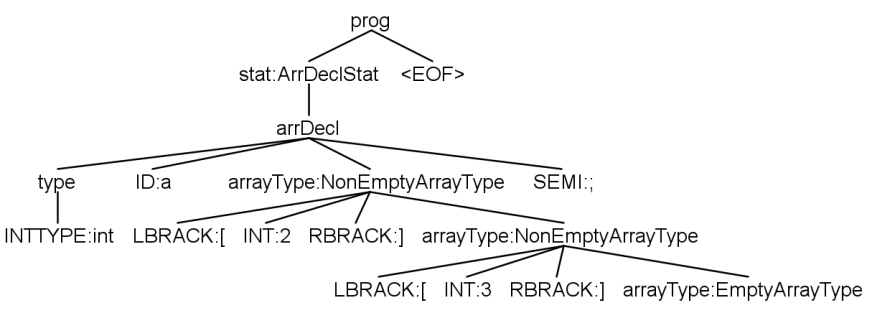
3.2 Listener
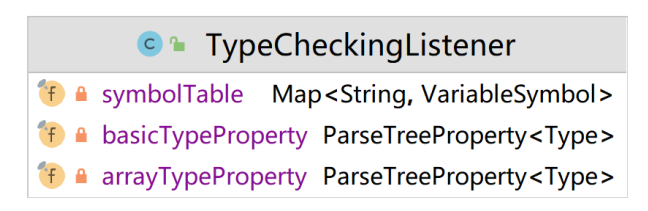
3.3 ParseTreeProperty
- 通过 ANTLR4 提供的
ParseTreeProperty<>来存储basicType与arrayType
1 | |
- 赋值语句类型检查,详见代码
4. 类型声明文法
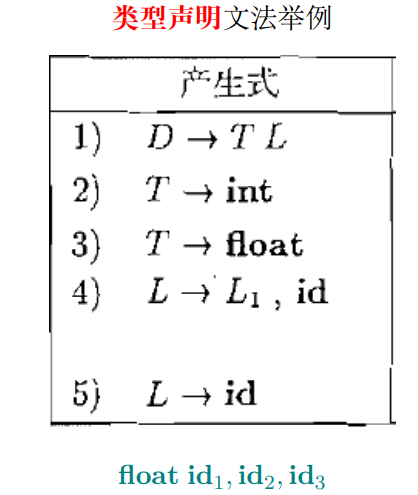
- 与数组类似,需要保存最左侧的类型
5. 类型系统
二、属性文法
1. 属性文法

$\textcolor{red}{\textbf{属性文法}\text{(Attribute Grammar)}:} 为上下文无关文法赋予\textcolor{blue}{\textbf{语义}}$
终结符或非终结符上的属性就可以看作语义
属性分为两类:
- 综合属性
- 继承属性
1.1 关键问题
如何基于上下文无关文法做上下文相关分析?
上下文相关文法分析复杂度太高
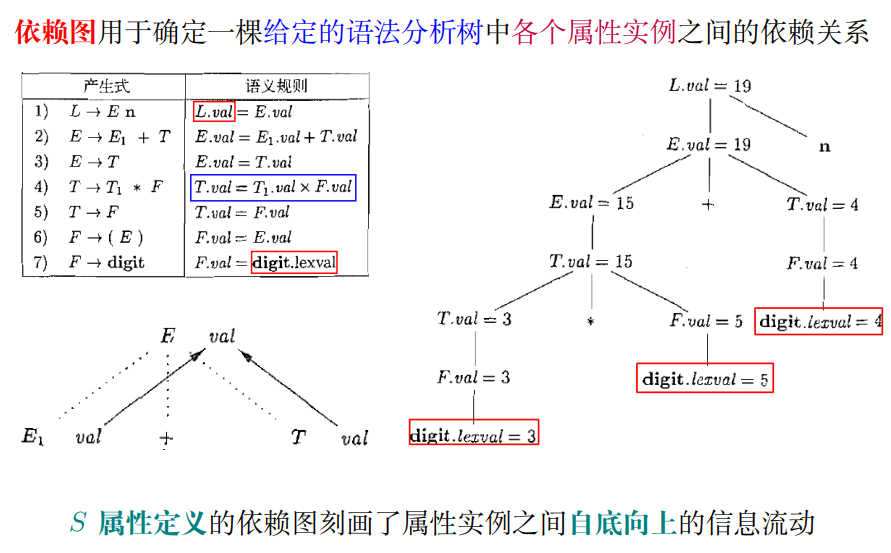
关键: 语法分析树上的有序信息流动
- 通过 DFS 来遍历
2. 计算属性值
2.1 Offline 方式
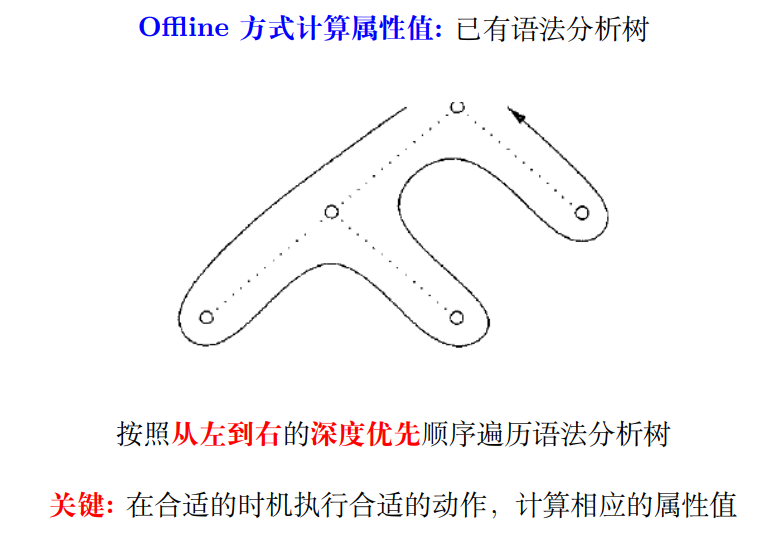
但因为要先建立语法分析树,实际上遍历了两遍,效率并不高
2.2 语法分析过程中
在语法分析过程中实现属性文法
基本思想: 一个动作在它左边的所有文法符号都处理过之后立刻执行

时机(Timing)
语义动作嵌入在什么地方? 这决定了何时执行语义动作。
2.3 实现迷你计算器
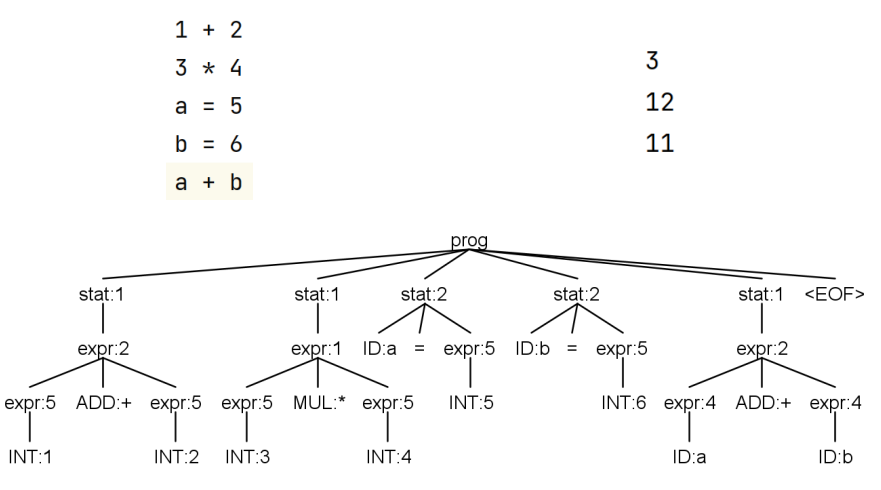
expr 的 value 只依赖于子节点的 value
1 | |
2.4 输出表格文件
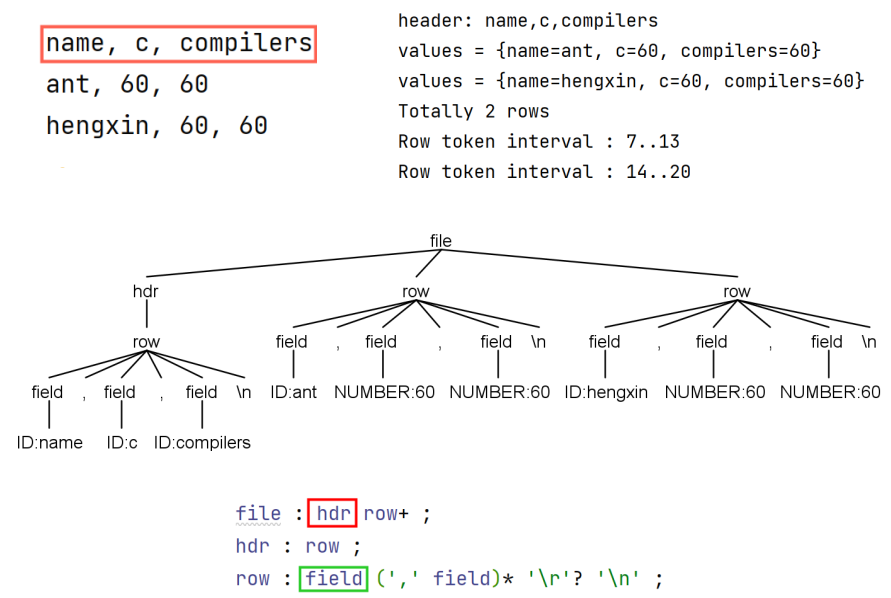
3. SDD
3.1 SDD
Definition (语法制导定义 (Syntax-Directed Definition; SDD))
SDD 是一个上下文无关文法和属性及规则的结合

要点:
- SDD 唯一确定了语法分析树上每个非终结符节点的属性值
- SDD 没有规定以什么方式、什么顺序计算这些属性值
3.2 注释语法分析树
注释(annotated)语法分析树: 显示了各个属性值的语法分析树
ANTLR4 中使用 ParseTreeProperty 存放属性值
ParseTreeProperty<Integer> put(ctx, ...) get(ctx, ...)
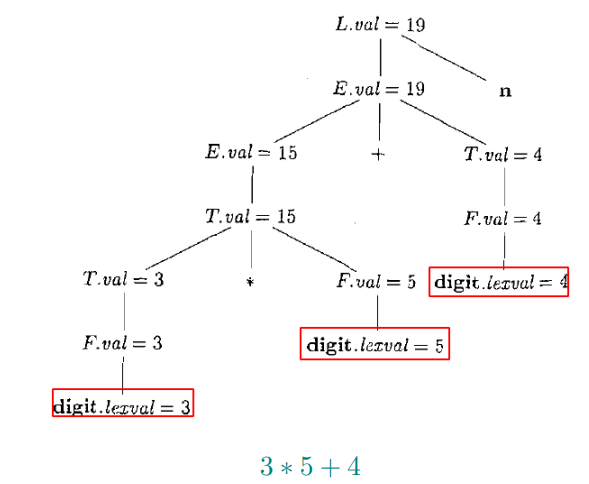
3.3 综合属性
Definition (综合属性 (Synthesized Attribute))

Definition ($S$ 属性定义 ($S$-Attributed Definition))
如果一个 SDD 的每个属性都是综合属性, 则它是 $S$ 属性定义
- 此类属性值的计算可以在 自顶向下 的 $LL$ 语法分析过程中实现
- 在 $LL$ 语法分析器中, 递归下降函数 A 返回 时, 计算相应节点 A 的综合属性值
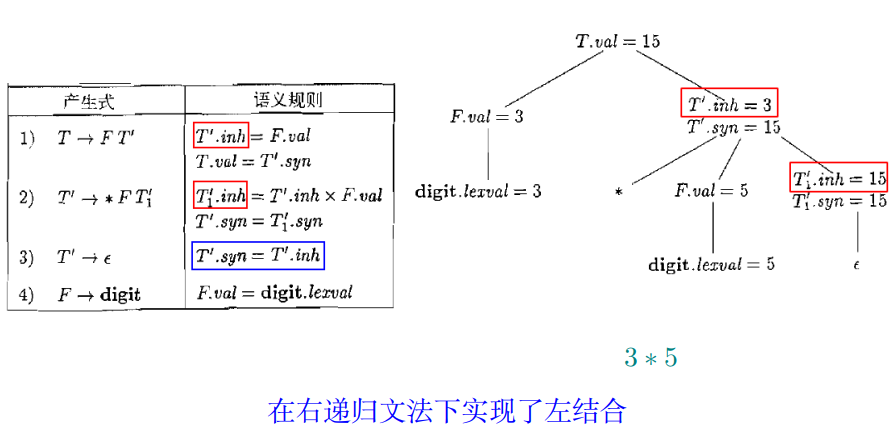
3.4 继承属性
Definition (继承属性 (Inherited Attribute))
节点 $N$ 上的继承属性只能通过 $N$ 的父节点、$N$ 本身和 $N$ 的兄弟节点上的属性来定义。
举例
$T$′ 有一个综合属性 $syn$ 与一个继承属性 $inh$
- 继承属性 $T$′.$inh$ 用于在表达式中从左向右传递中间计算结果
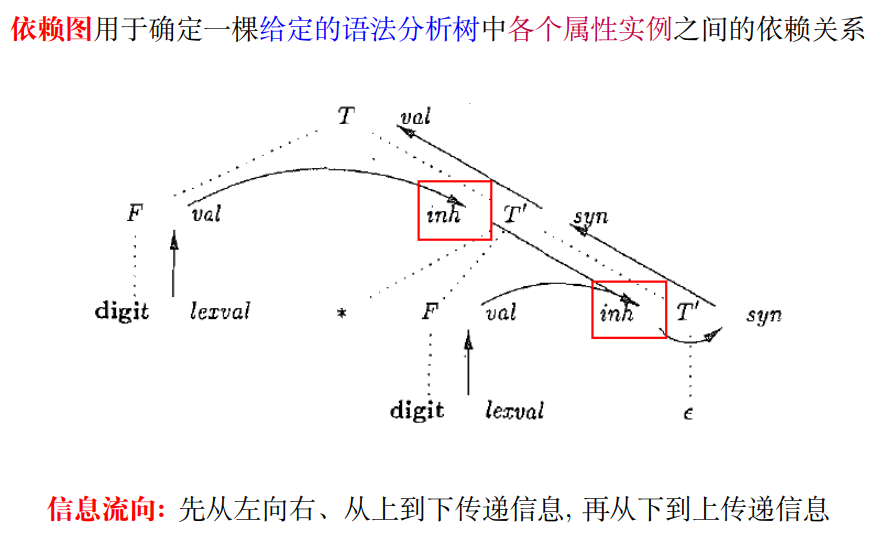
3.5 $L$ 属性定义
Definition ($L$ 属性定义 ($\textcolor{red}{L}$-Attributed Definition))

例1:非 $L$ 属性定义举例
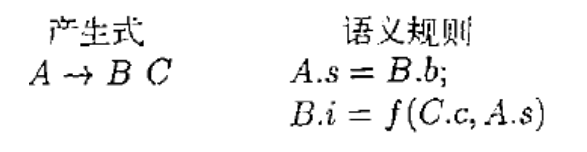
- $B.i$ 依赖了右兄弟节点的 $C.c$ 属性
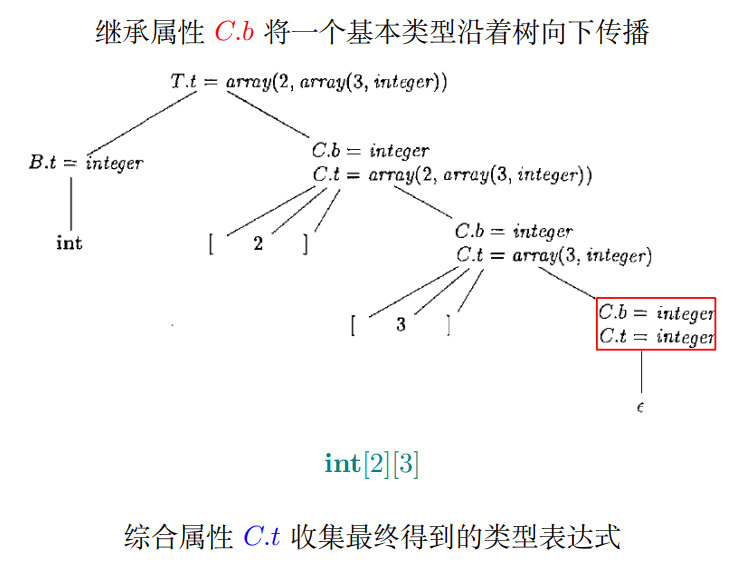
例2:数组类型文法举例

继承属性 $C.b$ 将一个基本类型沿着树向下传播
综合属性 $C.t$ 收集最终得到的类型表达式

例3:后缀表示

- (9 − 5) + 2 $\Rightarrow$ 95 − 2 +
- 9 − (5 + 2) $\Rightarrow$ 952 + −
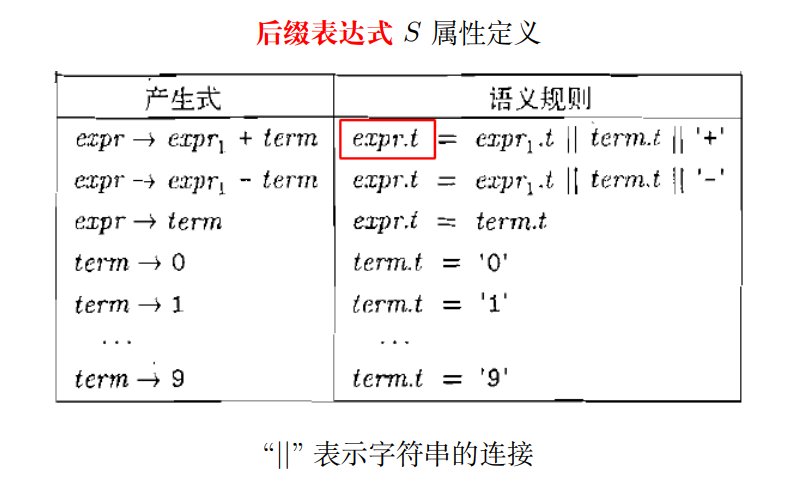
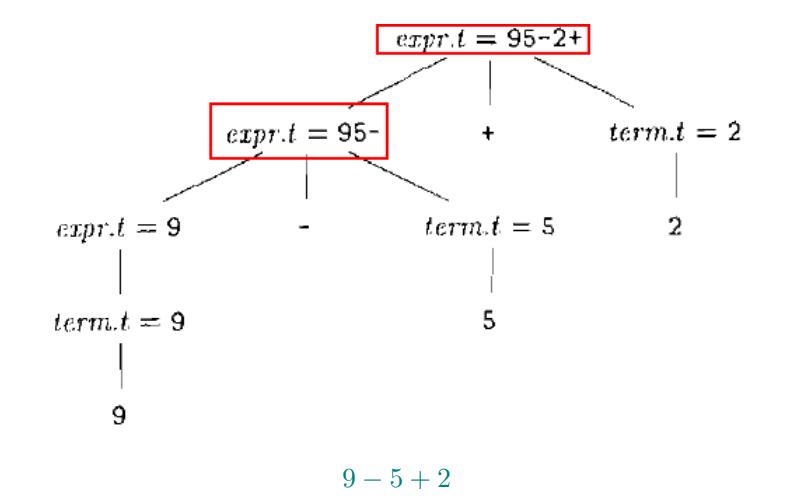
例4:有符号二进制数文法


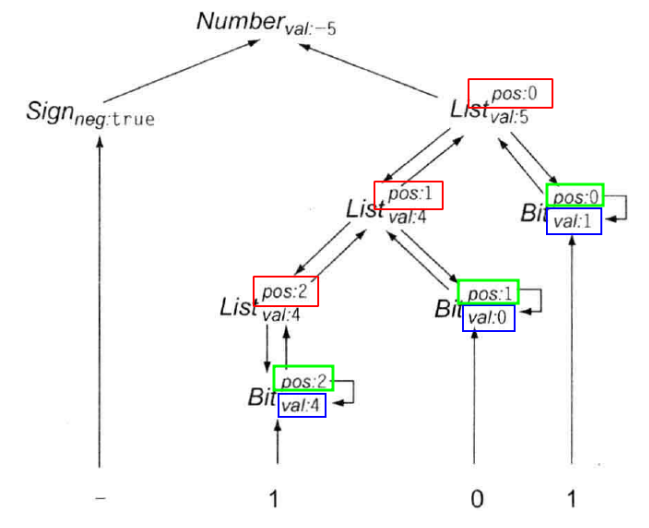
4. SDT
4.1 语法制导的翻译方案(SDT)
Definition (语法制导的翻译方案 (Syntax-Directed Translation Scheme; SDT))
SDT 是在其产生式体中嵌入语义动作的上下文无关文法。

$Q$ : 如何将带有语义规则的 SDD 转换为带有语义动作的 SDT
4.2 后缀翻译方案

4.3 $L$ 属性定义 与 $LL$ 语法分析
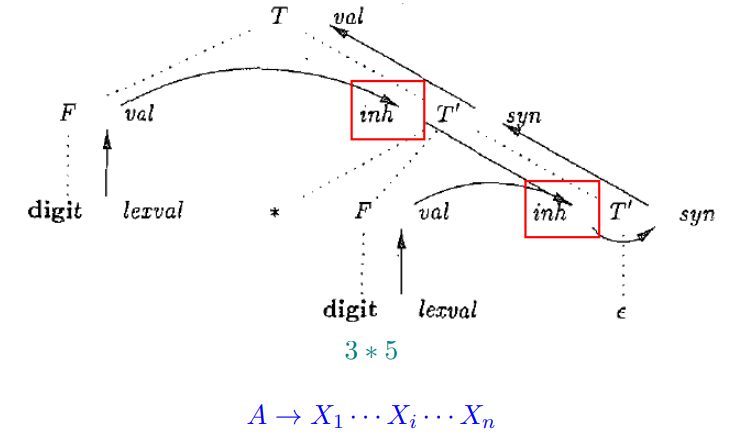
原则:
- 从左到右处理各个 $X_i$ 符号
- 对每个 $X_i$ , 先计算继承属性, 后计算综合属性
具体如下图所示

举例

4.4 左递归问题
许多工具是不支持左递归的,会转化为右递归,这会带来一些问题
- 因为 ANTLR4 支持直接左递归,暂不考虑

继承属性 $\textcolor{blue}{R.i}$ 用于计算并传递中间结果
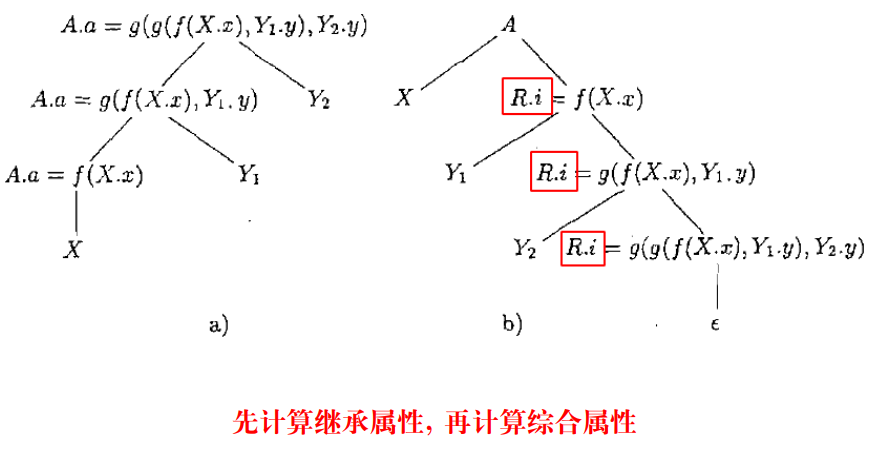
右递归翻译方案
原则: 继承属性在处理文法符号之前, 综合属性在处理文法符号之后



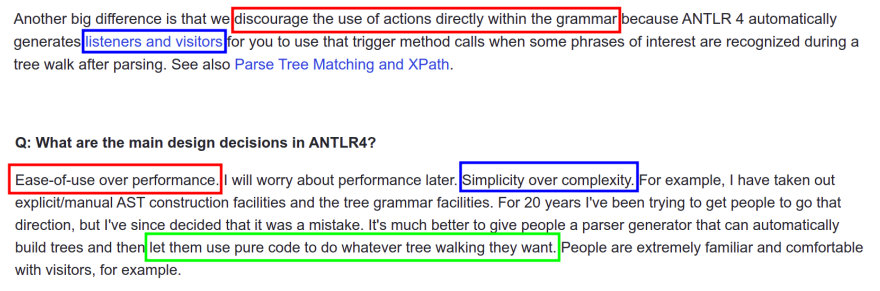
What is the difference between ANTLR 3 and 4?