数据库开发(1) 开发成功数据库的要点
0. 你应该了解的
- 关系代数
- 选择(select)、投影(project)、连接(join)、联合(union)、差(difference)、乘积 (product)
- DB,DBMS,基于数据库的应用程序
- 数据库的基本特性(表、KEY、完整性约束、锁、视图、事务…)
- SQL:基本的DDL,DML,触发器,存储过程等的语法和基本用法
- 数据库设计的基本原则
1. 开发成功数据库的要点
- 需要理解数据库体系结构
- 需要理解锁和并发控制特性:每个数据库都以不同的方式实现
- 不要把数据库当”黑盒”
- 性能、安全性都是适当的被设计出来的
- 用尽可能简单的方法解决问题:”创造”永远追不上开发的步伐
- DBA和RD之间的关系
1.1 数据库体系结构的差异
- 不能把数据库当成”黑盒”使用,因为每个数据库都是非常不同的
- Oracle和MySQL的差别,类似
- Windows和Linux的差别
- iOS和Android的差别
- 虽然都是DBMS,但它们也有相当的差异
- 了解这种差异,了解你所使用数据库的特性,是开发成功数据库应用的基础
1.2 并发控制的问题
- 现实存在并发,我们需要保持数据的一致性,所以要做并发控制
- 锁机制,使得并发控制成为可能
- 不同的数据库,实现锁机制是不一样的
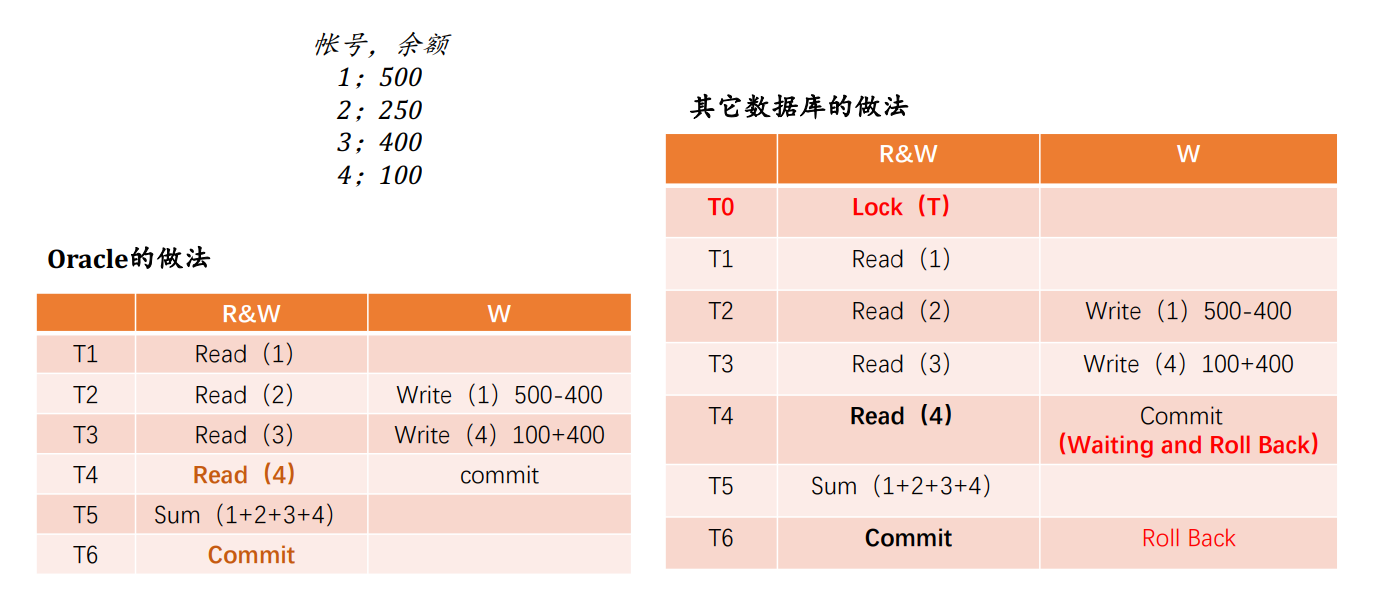
比如:Oracle的锁机制就比较特别

这个时候,Transaction1能提交吗?
- 可以的,结果是1000
Oracle存在有时读不到正确数据的现象
Oracle的多版本控制,读一致性的并发模型
- 读一致查询:对于一个时间点(point time),查询会产生一致的结果
- 非阻塞查询:查询不会被写入器阻塞,但在其它数据库中可能不是这样的
对于左侧,打开游标时,不会读取数据,只有在读取游标时才会读取数据
对于右侧,如果我们删除了所有的表,但是我们在Oracle中仍然可以使用之前打开的游标来读取那个时刻的数据
事实上,打开游标的时候确实没有复制,删除数据的时候也确实删除了,但是删除数据的时候Oracle为我们使用Undo日志来保存了下来(我们记作Undo statement),是删除的回滚段,游标从快照读出修改前的数据
Oracle这种锁机制的好处是什么?
- 读不阻塞写,可以极大程度上提高数据库的吞吐能力
- 读操作仅对业务有影响而对DB影响不大
Oracle/MySQL和其它数据库在并发上的差别
从体系结构和特性中了解具体数据库的锁机制
比如Oracle实现的锁机制
- 只有修改才加行级锁
- Read绝对不会对数据加锁
- Writer不会阻塞Reader
- 读写器绝对不会阻塞写入器
1.3 开发成功数据库应用的要点-黑盒的问题
对大多数码农而言,数据库锁机制好像都是自动和透明实现的,那么深入了解每个数据库的锁机制实现细节,对码农编码有什么影响嘛?
问题是:这对我们码农有什么影响吗?
Oracle的无阻塞设计有一个副作用,就是如果确实想保证一次最多只有一个用户访问一行数据,就得开发人员自己做一些工作
- 通过使用
FOR UPDATE手动加锁

黑盒和数据库独立性的问题
- 数据库有脱离实现级别的使用方法
- 我的观点是
- 要构建一个完全数据库独立的应用,而且是高度可扩展的应用是极其困难的
- 实际上,这几乎是不可能的
- 要构建一个完全数据库独立的应用
- 你必须真正了解每个数据库具体如何工作
- 如果你清楚每个数据库工作的具体细节,你就会知道,数据库独立性可能并不是你真正想要的
例如:Null值造成的数据库迁移障碍
null: 空值表示有一个值但是我不知道
对索引列进行空值比较将使 ORACLE 停用该索引,而一些条件判断可以通过索引高效完成,因此会极大影响效率
例子:在表T中,如果不满足某个条件,则找出X为NULL的所有行,如果满足就找出X等于某个特定值的所有行。
- Oracle并没有返回NULL(不知道)的所有行
- Oracle中NULL = NULL 返回 NULL
- 那么我们使用了is null关键字,但是Oracle不会为空值建立聚簇索引,导致性能会大幅度下降
- 于是我们通过创建了一个基于函数的索引来解决这个问题

关于黑盒的问题总结几点
- 数据库是不同的。在一个数据库上取得的经验也许可以部分应用于另一个数据库,但是必须有心理准备,二者之间可能存在一些基本差别,可能还有一些细微的差别。
- 细微的差别(比如对NULL的处理)与基本差别(如并发控制机制)可能有同样显著的影响。
- 应当了解数据库,知道它是如何工作的,他的特性如何实现,这是解决这些问题的唯一途径。
2. 优化
2.1 设计问题
我能不能找一个大牛帮我调优
- 先把程序写出来,之后再让专家在生产环境中帮我调优:这个想法是错误的。
- 性能调优(目前情况下性能优化至最优)
- 根据当前CPU能力、可用内存、I/O子系统等资源情况来设置相应参数
- 通过索引、物理结构、SQL的优化,具体提高某一个查询的性能
如果有个专家能通过一些参数、技巧提高了你的系统一个数量级的性能:不能说这个专家牛逼,大概只能说明你的程序太烂了。
性能拙劣的罪魁祸首是错误的设计
- 提高整体性能
- 技巧决定系统性能的下限
- 设计决定系统性能的上限
- 比如,新闻的门户网站
- 动态页面 vs 静态页面:百万量级的高并发下的动态网页导致大量的连接创建、I/O资源、CPU资源被消耗,导致负担过重
- 静态页面 + 内容管理系统:这个管理系统远远复杂于动态页面,使用触发器等自动化部署手段来生成静态网页
- 为什么微信不支持信息的修改?
- 因为微信朋友圈后台使用的NoSQL的非关系型数据库,所有的数据都是顺序存储,才能满足大量的读写效率。
- 顺序文件的修改是非常麻烦的,因此也就不支持了。
2.2 性能优化
性能优化要考虑整体
- 性能指标都是有成本的、安全和优化中寻找平衡
- 性能指标以吞吐量为核心(每秒处理多少事务)
- 而尽量不用一个事务几秒能处理完成
- 性能指标要考虑整体性
- 优化手段本身就有很大的风险,只不过你没意识到罢了
- 任何一个技术可以解决一个问题,但必然存在另一个问题的风险
- 对于带来的风险,控制在可接受的范围才是有成果
- 性能优化技术,使得性能变好,维持和变差是等概率的事件
使用优化工具
整体层面的性能优化考虑
问题一:CPU负载高,IO负载低
- 内存不够
- 磁盘性能差(磁盘问题、raid设计不好、raid降级)
- SQL的问题
- 并发锁机制的问题
- 事务设计问题,大量小数据IO
- 大量的全表扫描
问题二:IO负载高,CPU负载低
- 大量小的IO执行写操作
- Autocommit,产生大量小IO
- 大量大的IO执行写操作
- SQL的问题
- IO/PS磁盘限定一个每秒最大IO次数
问题三:IO和CPU负载都高
- 硬件不够用了
- SQL存在问题
性能问题,90%的问题来源都是程序员的问题,开发环境到生产环境是一场灾难
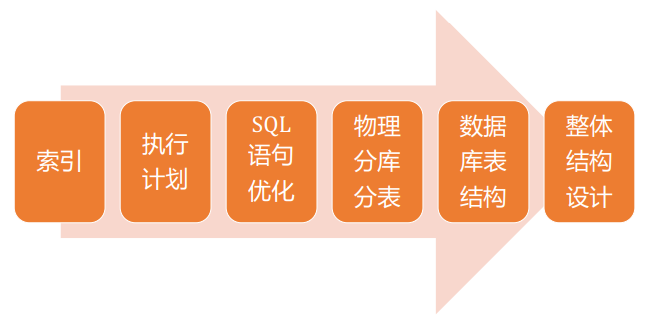
SQL优化的方向
限用Boolean型字段
- SQL中并不存在Boolean类型
- 实现flag表示标志位的Y/N或T/F
- 例如:order_completed
- 但是…往往增加信息字段能包含更多的信息量
- 例如:completion_date completion_by
- 或者增加order更多状态标示
- 极端的例子:四个属性取值都是T/F,可以用0-15这16个数值代表四个属性所有组合状态
- 技巧可能违反了原子性的原则
- 为数据而数据,是通向灾难之路
理解子类型(SubType)
- 表过”宽”(有太多属性)的另一个原因,是对数据项之间的关系了解不够深入
- 一般情况下,给子类型表指定完全独立于父表主键的主键,是极其错误的
约束应明确说明
- 数据中存在隐含约束是一种不良设计
- 字段的性质随着环境变化而变化时设计的错误和不稳定性
- 数据语义属于DBMS,别放到应用程序中
过于灵活的危险性
- “真理向前跨一步就是谬误”
- 不可思议的四通用表设计
- Objects(oid, name), Attributes(attrid, attrname, type)
- Object_Attributes(oid,attrid,value)
- Link(oid1,oid2)
- 随意增加属性,避免NULL
- 成本急剧上升,性能令人失望
如何处理历史数据
- 历史数据:例如:商品在某一时刻的价格
- Price_history(article_id, effective_from_date, price)
- 缺点在于查询当前价格比较笨拙
- 其他方案
- 定义终止时间
- 同时保持价格生效和失效日期,或生效日期和有效天数等等
- 当前价格表+历史价格表
处理流程
- 操作模式(operating mode)
- 异步模式处理(批处理)
- 同步模式处理(实时交易)
- 处理数据的方式会影响我们物理结构的设计