Abstract
本项目主要是针对于 YOLO v11的网络结构进行优化,来实现体积压缩和提高模型速度
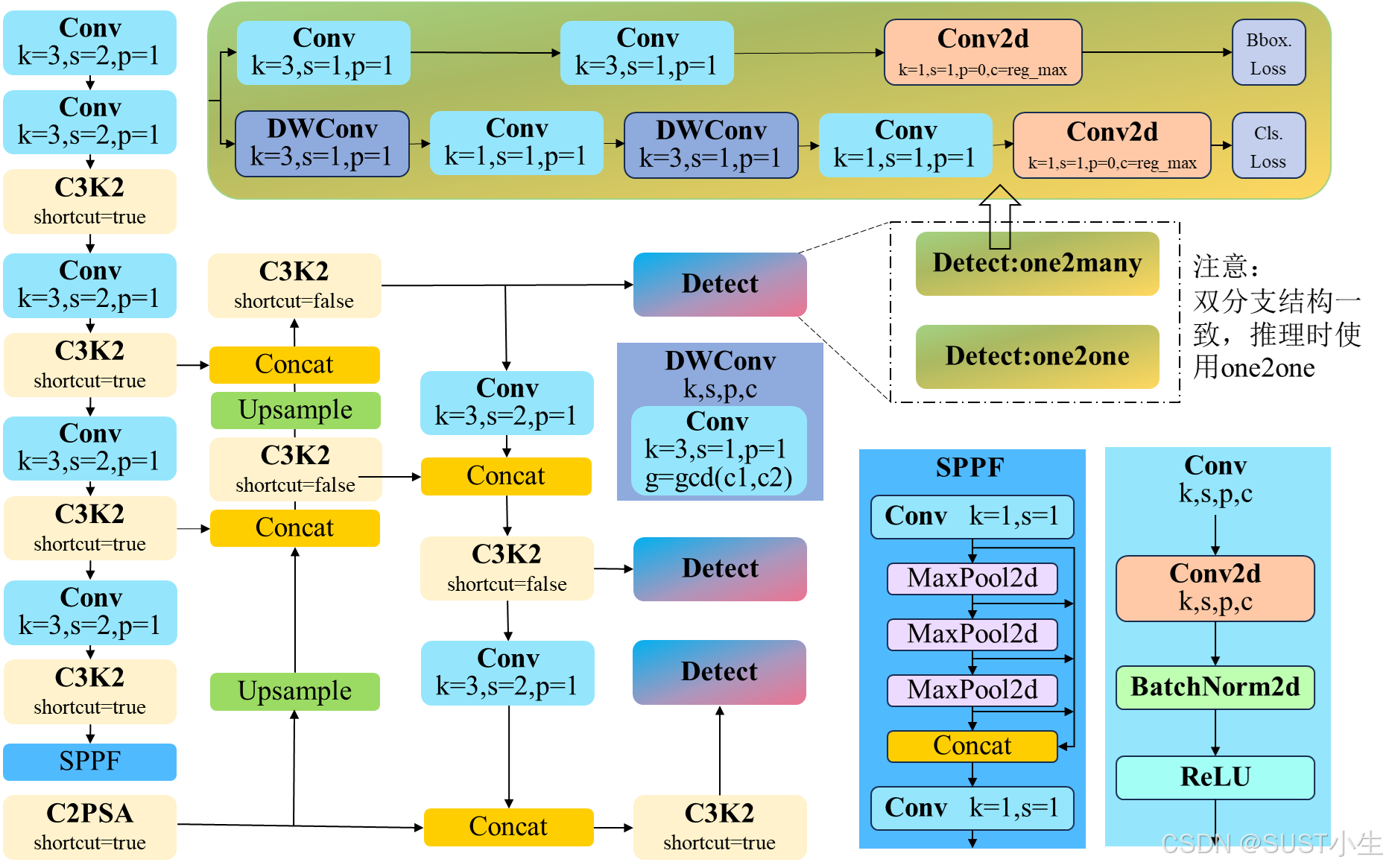
[!NOTE] 以下是 YOLO v11的模型结构图
数据清洗
[!NOTE] 由于在网络上没有相关手写体的YOLO数据集,所以我们要通过别人其他模型的数据集来自己构建一个与YOLO模型适配的数据集
首先我们需要关于手写体的基本数据集
[!WARNING] 首先这个数据集是缺少了YOLO所需要的坐标和类别等要求的,所以我们需要自己用PYTHON自动化来实现将其转换为YOLO所需要的格式

这个是满足YOLO的框的坐标格式 1 表示类别,后面表示中心坐标和长宽
1 0.500000 0.500000 1.000000 1.000000以下附有代码
import os
import shutil
from pathlib import Path
def generate_yolo_txt(image_path, class_id, output_dir, class_name):
"""
为一张图片生成 YOLO 格式的 txt 文件,并复制图片和 txt 到目标文件夹的 images 和 labels 子文件夹
image_path: 源图片路径
class_id: 类别 ID(从文件夹名称最后两个数字提取)
output_dir: 目标文件夹路径
class_name: 类别的文件夹名称(用于文件名加前缀)
"""
try:
# 构造 txt 文件内容
x_center, y_center, width, height = 0.5, 0.5, 1.0, 1.0
txt_content = f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n"
base_name = f"{class_name}_{image_path.name}"
target_img_path = output_dir / "images" / base_name
target_txt_path = output_dir / "labels" / Path(base_name).with_suffix(".txt")
print(f"目标图片路径:{target_img_path}")
print(f"目标 txt 路径:{target_txt_path}")
# 创建目标目录
target_img_path.parent.mkdir(parents=True, exist_ok=True)
target_txt_path.parent.mkdir(parents=True, exist_ok=True)
# 写入 txt 文件
with open(target_txt_path, "w") as f:
f.write(txt_content)
# 复制图片
shutil.copy2(image_path, target_img_path)
print(f"成功生成并复制:{target_img_path} 和 {target_txt_path}")
except Exception as e:
print(f"处理 {image_path} 时出错:{e}")
def process_folder(root_dir, output_dir):
"""
遍历大文件夹,生成 YOLO txt 文件并复制到目标文件夹的 images 和 labels 子文件夹
root_dir: 源大文件夹路径
output_dir: 目标文件夹路径
"""
root_path = Path(root_dir)
output_path = Path(output_dir)
# 检查源文件夹是否存在
if not root_path.exists():
print(f"错误:源文件夹 {root_path} 不存在!")
return
print(f"源文件夹绝对路径:{root_path.resolve()}")
# 创建目标文件夹及其子文件夹
try:
# 注释清空逻辑以保留现有文件,方便调试
# if output_path.exists():
# shutil.rmtree(output_path)
output_path.mkdir(parents=True, exist_ok=True)
(output_path / "images").mkdir(parents=True, exist_ok=True)
(output_path / "labels").mkdir(parents=True, exist_ok=True)
except PermissionError:
print(f"错误:无法创建目标文件夹 {output_path} 或其子文件夹,请检查权限!")
return
# 遍历大文件夹中的小文件夹
for folder in root_path.iterdir():
if not folder.is_dir():
continue
folder_name = folder.name
# 提取文件夹名称最后两个数字作为 class_id
try:
class_id = int(folder_name[-2:])
except ValueError:
print(f"错误:无法从文件夹 {folder_name} 提取最后两个数字作为 class_id,跳过!")
continue
print(f"开始处理文件夹:{folder_name} (class_id: {class_id})")
images = list(folder.glob("*.[pP][nN][gG]"))
print(f"文件夹 {folder_name} 中的图片:{images}")
for image_path in images:
print(f"处理图片:{image_path}")
generate_yolo_txt(image_path, class_id, output_path, folder_name)
# 打印处理的文件夹和对应的 class_id
print("\n处理的文件夹和 class_id:")
for folder in root_path.iterdir():
if folder.is_dir():
try:
class_id = int(folder.name[-2:])
print(f"{folder.name}: {class_id}")
except ValueError:
print(f"{folder.name}: 无法提取 class_id")
if __name__ == "__main__":
dataset_dir = "./English/Img/BadImag/Bmp" #目标文件夹
output_dir = "output_dataset" # 目标生成文件夹
process_folder(dataset_dir, output_dir)
进行 适配YOLO模型训练的数据集划分
[!NOTE] 训练集划分包括 模型训练部分,模型验证部分,如下图所示

import os
import shutil
import random
# 原始数据路径
base_dir = './'
dataset_dir = os.path.join(base_dir, 'output_dataset')
images_dir = os.path.join(dataset_dir, 'images')
labels_dir = os.path.join(dataset_dir, 'labels')
# 新的输出路径(不在 DATA1.0 下)
output_dir = os.path.join(base_dir, 'dataset')
train_images_dir = os.path.join(output_dir, 'images', 'train')
val_images_dir = os.path.join(output_dir, 'images', 'val')
train_labels_dir = os.path.join(output_dir, 'labels', 'train')
val_labels_dir = os.path.join(output_dir, 'labels', 'val')
# 创建新目录
os.makedirs(train_images_dir, exist_ok=True)
os.makedirs(val_images_dir, exist_ok=True)
os.makedirs(train_labels_dir, exist_ok=True)
os.makedirs(val_labels_dir, exist_ok=True)
# 收集所有图像文件
image_files = [
f for f in os.listdir(images_dir)
if f.lower().endswith(('.jpg', '.jpeg', '.png'))
and os.path.isfile(os.path.join(images_dir, f))
]
# 打乱顺序
random.shuffle(image_files)
# 划分比例
split_ratio = 0.8
split_index = int(len(image_files) * split_ratio)
train_images = image_files[:split_index]
val_images = image_files[split_index:]
# 复制训练集
for img in train_images:
base_name, ext = os.path.splitext(img)
label = base_name + '.txt'
# 图像复制
shutil.copy(os.path.join(images_dir, img), os.path.join(train_images_dir, img))
# 标签复制
label_src = os.path.join(labels_dir, label)
label_dst = os.path.join(train_labels_dir, label)
if os.path.exists(label_src):
shutil.copy(label_src, label_dst)
else:
print(f"[警告] 缺失标签文件: {label_src}")
# 复制验证集
for img in val_images:
base_name, ext = os.path.splitext(img)
label = base_name + '.txt'
# 图像复制
shutil.copy(os.path.join(images_dir, img), os.path.join(val_images_dir, img))
# 标签复制
label_src = os.path.join(labels_dir, label)
label_dst = os.path.join(val_labels_dir, label)
if os.path.exists(label_src):
shutil.copy(label_src, label_dst)
else:
print(f"[警告] 缺失标签文件: {label_src}")
print(f"✅ 数据集划分完成,训练集:{len(train_images)},验证集:{len(val_images)}")
print(f"✅ 输出路径:{output_dir}")
结果:
::: warning
注意
划分数据集进行训练的时候需要保证每一个类别都应该有 训练的数据 和 推理的数据,如果存在不同类别需要在这个代码上进行细微调整(数据集划分的时候进行图片选择的时候,我们可以基于每一种类别的图片进行划分)
:::

模型训练
进行完数据集划分,现在可以进行模型训练了。 我是使用的 MAC,所以 device 是使用的 mps,如果是 windows的话,可以使用 GPU加速会快很多。
from ultralytics import YOLO
model = YOLO('yolo11n.pt')
model.train(
data='data.yaml', # Path to the data configuration file
epochs=5, # Number of training epochs
imgsz=640, # Image size for training
batch=2, # Batch size
name='yolov8_custom', # Name of the training run
device='mps' # Use GPU (0 for first GPU, 'cpu' for CPU)
)
results = model.val()模型剪枝
参考相关文章 Learning Efficient Convolutional Networks Through Network Slimming 进行完模型训练后。
[!WARNING] 由于 我们想设计一个 便于在一些内存小的开发板上进行运行的模型,所以我们可以进行一些模型压缩,或者量化进行处理。这里我们采用的是模型剪枝操作。
我们采用的是L1正则化剪枝来对YOLO的网络结构进行剪枝,这里我们可以简单的介绍一下什么是 L1正则化剪枝流程
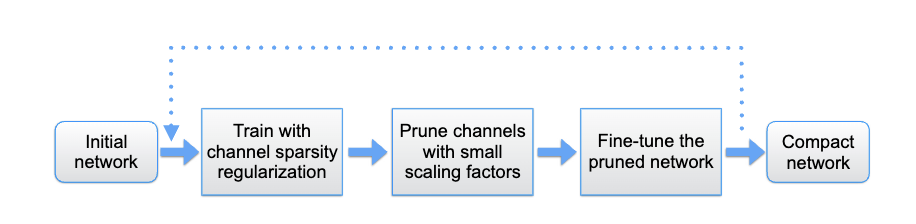 这是一个基本的流程,具体的操作都是可以基于 YOLO的网络结构训练代码进行修改的。
接下来我们进行一个详细的介绍
这是一个基本的流程,具体的操作都是可以基于 YOLO的网络结构训练代码进行修改的。
接下来我们进行一个详细的介绍
[!NOTE] 这里的剪枝代码没有给出
通道权重压缩
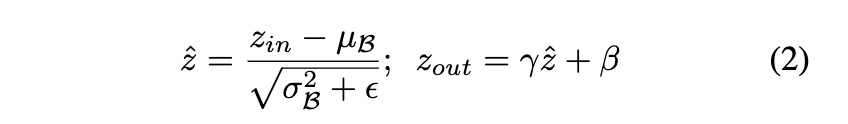
[!NOTE] 归一化就相当于把所有值通过比值关系,全部压缩到 0~1之间
这个是通道进行剪枝的计算公式来对L1层中的通道进行归一化处理,我们先进行 归一化处理,也可以称为约束训练,这是在训练过程中添加的部分
# 对BN层进⾏L1正则化,约束训练时启⽤,正常训练时注释掉
l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs)
for k, m in self.model.named_modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data))
m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data))
进行完约束训练后,会生成一个训练的模型(.pt),然后我们再针对于这个 .pt 模型,进行模型剪枝,剪枝的操作相当于会删除网络结构中 权重小(影响因子小)的节点和边,从而实现稀少少量精度来实现压缩体积加快速度的效果。 然后通过完剪枝的模型我们不能直接就进行图片推理,我们需要先进行回调训练,通过回调训练将模型的精度进行一下调整。 就是将约束训练增加的代码给注释掉再进行训练就可以了。
这样剪枝的整个操作就实现完整了!