对抗生成网络
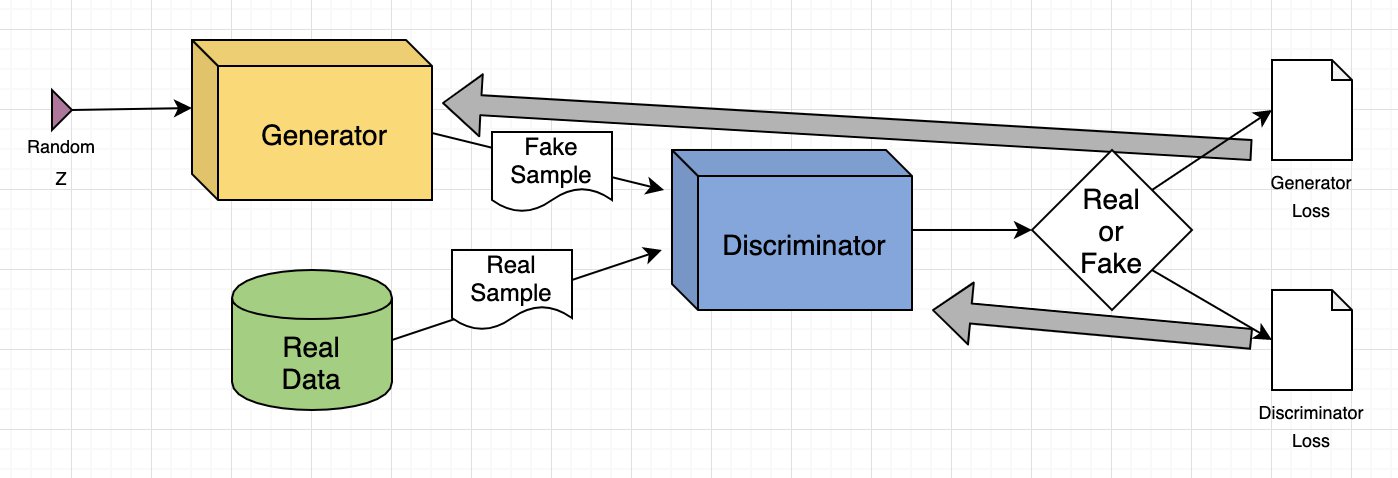
模型结构
- 生成模型 G: 捕捉数据分布
- 判别模型 D: 估计样本来自训练数据还是 G的概率(判别是真的还是假的的概率)
训练方式
数据要求: 以张量的形式传入[M, N, K]
- 基于反向传播机制
minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
-
判别器 D 的目标maxDV(D,G)→Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
-
生成器 G 的目标就是最小化 D 的目标价值,→minG(maxDV(D,G))
-
在实际G的模型训练中,由于一开始的生成网络与实际网络差异大,D(G(z)) 更趋向于 0,所以 G难以从 判别器D中获得梯度信号,难以改进生成能力,所以训练G时,可以最大化(logD(G(z)))
训练机制
交替进行 k步 D优化, 一步G优化
- 训练判别器 D
1.1 批量训练的平均损失函数
m1i=1∑m[logD(x(i))+log(1−D(G(z(i))))]
1.2 梯度计算
∇θdm1i=1∑m[logD(x(i))+log(1−D(G(z(i))))]
1.3 参数更新
θd←θd+α∇θdLD
LD 是判别器的损失函数,α 是学习率
- 训练生成器 G
**原始目标:最小化 log(1−D(G(z))→ 最大化 log(D(G(z))) **
2.1 批量训练的平均损失函数
m1i=1∑m[log(1−D(G(Z(i))))]
2.2 梯度计算
∇θdm1i=1∑m[log(1−D(G(zi))]
2.3 参数更新
θg←θg−α∇θgLG
注意: 进行 G更新的时候,判别器 D的参数是冻结的
CycleGAN
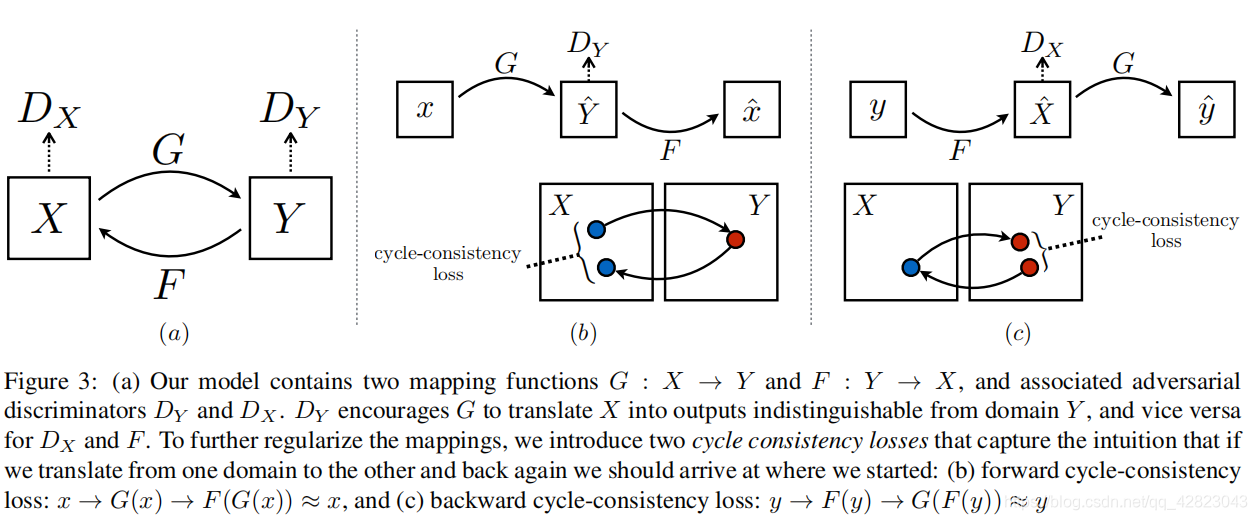
模型结构
-
两个生成模型 G 和 F:
- 生成器 G: 学习将图像从域 X 转换到域 Y 的映射,即 G:X→Y
- 生成器 F: 学习将图像从域 Y 转换到域 X 的映射,即 F:Y→X
-
两个判别模型 DX 和 DY:
- 判别器 DY: 区分图像是来自目标域 Y 的真实图像还是由 G 生成的假图像 G(x)
- 判别器 DX: 区分图像是来自目标域 X 的真实图像还是由 F 生成的假图像 F(y)
训练方式
CycleGAN的训练目标是学习两个映射 G 和 F,使得:
- G(x) 的图像与域 Y 中的图像无法区分
- F(y) 的图像与域 X 中的图像无法区分
为了实现无监督训练,提出了循环一致性损失(Cycle Consistency Loss)
- 前向循环一致性: x→G(x)→F(G(x))≈x
- 后向循环一致性: y→F(y)→G(F(y))≈y
整个优化目标函数是对抗性损失(Adversarial Loss)和循环一致性损失的加权和
联合损失函数
L(G,F,DX,DY)=LGAN(G,DY,X,Y)+LGAN(F,DX,Y,X)+λLcyc(G,F)
其中 λ 是循环一致性损失的权重
1. 对抗性损失 (Adversarial Loss)
CycleGAN 使用标准的 GAN 损失来提高生成的图像与目标域中的图像分布匹配准确率
1.1 生成器 G 和 判别器 DY 的对抗损失: 鼓励 G(x) 看起来像真实图像 Y
LGAN(G,DY,X,Y)=Ey∼pdata(y)[logDY(y)]+Ex∼pdata(x)[log(1−DY(G(x)))]
相关概念
-
判别器 DY 的目标是最大化 LGAN(G,DY,X,Y)
-
生成器 G 的目标是最小化 LGAN(G,DY,X,Y)
-
G 通常会最大化 Ex∼pdata(x)[logDY(G(x))] 以避免早期训练不稳定。
1.2 生成器 F 和 判别器 DX 的对抗损失: 鼓励 F(y) 看起来像真实图像 X
LGAN(F,DX,Y,X)=Ex∼pdata(x)[logDX(x)]+Ey∼pdata(y)[log(1−DX(F(y)))]
相关概念
- 判别器 DX 的目标是最大化 LGAN(F,DX,Y,X)
- 生成器 F 的目标是最小化 LGAN(F,DX,Y,X)
- 在实际训练中,F 通常会最大化 Ey∼pdata(y)[logDX(F(y))]
2. 循环一致性损失 (Cycle Consistency Loss)
循环一致性损失确保了转换的可逆性,防止生成器学习到将源域中的所有图像映射到目标域中的相同图像,从而避免“模式崩溃”,就是降低泛化能力
2.1 前向循环一致性损失:
Lcyc(G,F)=Ex∼pdata(x)[∣∣F(G(x))−x∣∣1]
2.2 后向循环一致性损失:
Lcyc(G,F)=Ey∼pdata(y)[∣∣G(F(y))−y∣∣1]
常见使用 L1 范数 (∣∣⋅∣∣1) 来计算循环一致性损失
训练机制
CycleGAN 的训练也采用交替优化策略,同时优化两个生成器和两个判别器
- 训练判别器 DX 和 DY:
对于 DY: 使用来自域 Y 的真实图像 y 和由 G 生成的假图像 G(x) 来计算损失并更新参数
批量训练的平均损失函数(以 DY 为例,目标是最大化):
m1i=1∑m[logDY(y(i))+log(1−DY(G(x(i))))]
1.1 梯度计算:
∇θDYm1i=1∑m[logDY(y(i))+log(1−DY(G(x(i))))]
1.2 参数更新:
θDY←θDY+α∇θDYLGAN(G,DY,X,Y)
1.3 对于 DX: 类似地,使用来自域 X 的真实图像 x 和由 F 生成的假图像 F(y) 来计算损失并更新参数
- 训练生成器 G 和 F:
对于 G 和 F:
计算包括对抗损失和循环一致性损失在内的总损失 * 批量训练的平均损失函数(以 G 为例,目标是最小化其对抗部分,并最小化循环一致性部分):
m1i=1∑m[−logDY(G(x(i)))]+λm1i=1∑m[∣∣F(G(x(i)))−x(i)∣∣1]
2.1 梯度计算:
∇θG(m1i=1∑m[−logDY(G(x(i)))]+λm1i=1∑m[∣∣F(G(x(i)))−x(i)∣∣1])
2.2 参数更新:
θG←θG−α∇θGLtotal
注意: 进行 G 和 F 更新时,判别器 DX 和 DY 的参数是冻结的
DCGAN
Pytorch代码库
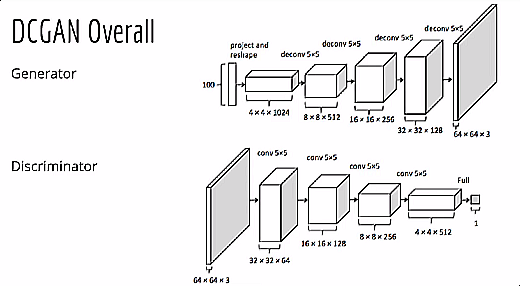
摘要翻译
以下是该论文摘要部分的翻译:
近年来,使用卷积网络(CNNs)的监督学习在计算机视觉应用中得到了广泛的应用 。相比之下,使用CNNs的无监督学习受到的关注较少 。在这项工作中,我们希望能帮助缩小CNNs在监督学习和无监督学习方面成功应用之间的差距 。我们引入了一类名为深度卷积生成对抗网络(DCGANs)的CNN,它们具有特定的架构约束,并证明了它们是无监督学习的有力候选者 。通过在各种图像数据集上进行训练,我们展示了令人信服的证据,表明我们的深度卷积对抗对(deep convolutional adversarial pair)在生成器和判别器中都学习到了从对象部分到场景的层次化表示 。此外,我们将学习到的特征用于新颖的任务——展示了它们作为通用图像表示的适用性 。
研究方法
提出 深度卷积GANs(DCGAN),其实就是针对于 生成器和判别器两个神经网络进行结构调整,将全连接网络改成CNN卷积神经网络
-
用跨步卷积(判别器)和分数步长卷积(生成器)替换所有池化层
-
在生成器和判别器中都使用批量归一化(batchnorm)
-
对于更深层的架构,移除全连接隐藏层
-
在生成器中,除使用Tanh的输出层外,所有层都使用ReLU激活函数
-
在判别器中,所有层都使用LeakyReLU激活函数
StyleGAN
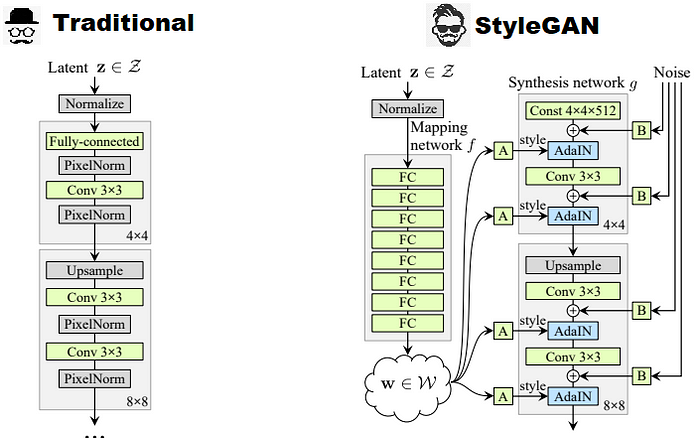
摘要翻译
我们为生成对抗网络(GANs)提出了一种替代性的生成器架构,该架构借鉴了风格迁移领域的文献。
这种新架构能够自动地、无监督地将高层级属性(例如,在人脸数据上训练时学到的姿态和身份)与生成图像中的随机变化(例如,雀斑、头发)分离开来。同时,它还实现了对合成过程直观的、特定尺度的控制。
在传统的分布质量指标方面,新的生成器提升了当前顶尖水平(state-of-the-art)的表现,并展现出更好的插值特性,也能更好地解耦变化的潜在因子。为了量化插值质量和解耦程度,我们提出了两种新的、适用于任何生成器架构的自动化评估方法。
最后,我们引入了一个全新的、高度多样化且高质量的人脸数据集。
研究方法
针对于 GAN的生成器的结构进行改良
- 将随机噪声 Z 输入 Mapping network(非线形映射网络f:Z→W,通过 MLP多层感知机实现) 中,将 Z 转化为 W,W 在第k层通过仿射变换形成(ys,k,yb,k),影响每一层的特征值归一化
- 对每一个通道的特征向量进行归一化
相关概念: 将 Z→W 将Z(存在属性纠缠)转化到 W空间,更容易找到图像的独立属性
AdaIN(x,y)=ys,iσ(xi)xi−μ(xi)+yb,i(1)
相关概念:
- W 专门化分为风格 y=(ys,yb)
- xi 表示每一个通道的特征值
WGAN
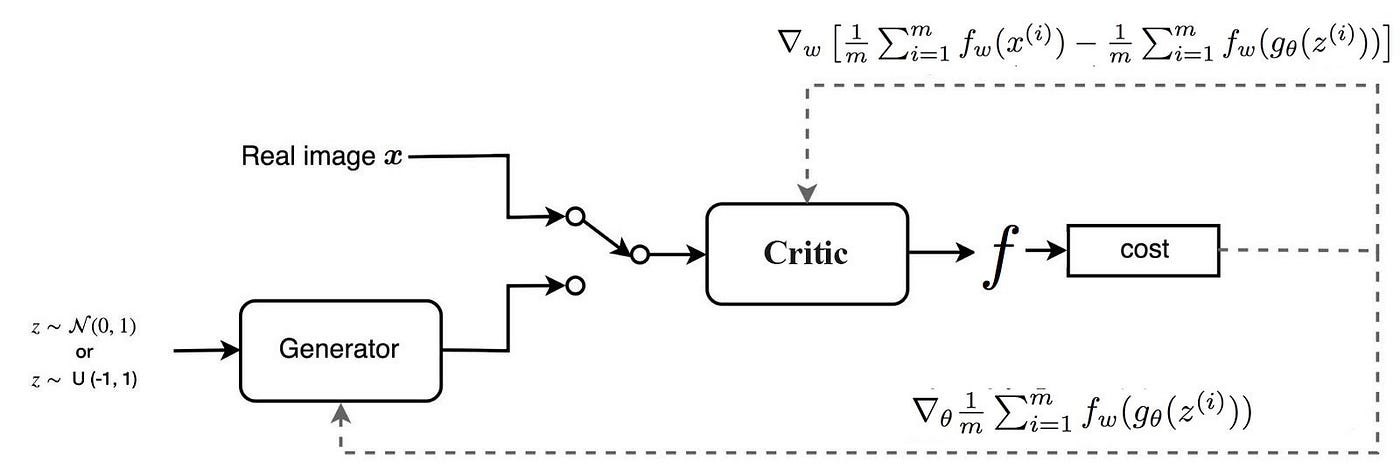
研究方法
修改了 传统的GAN的损失函数
总体的损失函数
gθminfw∈FLmax(Ex∼Pr[fw(x)]−Ez∼p(z)[fw(gθ(z))])
判别器损失函数 LD
LD=Ex∼Pr[fw(x)]−Ez∼p(z)[fw(gθ(z))](3)
相关概念
- fw是判别器网络(神经网络),实际上是 Earth Mover(EM)距离,可以理解为会识别这个数据和真实数据的相似程度,有一个上界K
生成器损失函数 LG
LG=−Ez∼p(z)[fw(gθ(z))]